HKLM\Software\Policies\Microsoft\Windows\WcmSvc\GroupPolicy
타입: DWORD32 이름: fMinimizeConnections 값 : 0
'분류 전체보기'에 해당되는 글 478건
- 2020.12.22 듀얼랜 구성시 wifi 자동연결이 안될 때
- 2020.09.16 xcopy 통째로 복사
- 2020.07.06 맥북 .파일 보기
- 2018.02.21 데몬 스크립트 작성 및 등록하기
- 2018.02.20 스크립트 포멧 오류가 날 때 확인
- 2018.02.20 웹서버 설정(apache2, php, mariadb)
- 2018.02.20 웹폴더 권한 설정
- 2011.12.20 Excel 창 두개 띄우기
- 2011.08.16 하위 디렉토리 파일 검색 및 삭제
- 2011.08.14 모래속 진주같은 영화, Sucker Punch
- 2011.07.11 우산 속의 그녀(?)
- 2011.07.06 영어 관련 사이트
- 2011.02.19 하드 추가 장착 및 자동 마운트
- 2011.02.19 hostname 변경
- 2011.02.17 big-endian and little-endian
- 2011.02.12 iso 이미지 만들기, cd 굽기
- 2011.01.26 [error] E: Sub-process /usr/bin/dpkg returned an error code (1)
- 2011.01.14 Repo 설치 및 설정
- 2010.11.19 표준 함수
- 2010.11.18 OSI (Open Systems Interconnection) ; 개방형 시스템간 상호 접속
- 2010.11.18 layer and layering ; 계층, 계층화
- 2010.11.18 Jolt
- 2010.11.18 IT (information technology) ; 정보기술
- 2010.11.18 ISV (independent software vendor)
- 2010.11.18 IS (information system[s] or information services) ; 정보시스템 또는 정보서비스
- 2010.11.18 interoperability ; 상호 운용성
- 2010.11.18 기억 부류
- 2010.11.17 popJazzSmooth
- 2010.11.17 함수
- 2010.11.16 instruction ; 명령어
xcopy 원본폴더 타겟폴더 /s /k /e /c /h /r /y
'etc' 카테고리의 다른 글
| Excel 창 두개 띄우기 (0) | 2011.12.20 |
|---|---|
| popJazzSmooth (0) | 2010.11.17 |
| 깡통파일(더미파일) 만들기 (0) | 2010.09.01 |
| Source Insight 3.5 떠있는 창 10개로 제한하기 (0) | 2010.07.09 |
| SourceInsight 한글 주석 깨지지 않게하기 (0) | 2010.07.09 |
$ defaults write com.apple.Finder AppleShowAllFiles true
$ killall Finder
command + . + shift 눌러도 됨
1. 일단 스크립트 작성
#!/bin/sh
cd /var/www/html
sudo echo-service start
2. /etc/init.d에 복사
3. 권한 변경 및 등록
sudo update-rc.d echo.sh defaults
sudo chmod +x echo.sh4. insserv 경고 대처 (무시해도 상관 없다)
스크립트에 LSB Tags 넣기
#!/bin/sh
### BEGIN INIT INFO
# Provides: turtlelab
# Required-Start: $remote_fs
# Required-Stop: $remote_fs
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Start Echo daemon at boot time
# Description: Enable service provided by daemon.
### END INIT INFO
cd /var/www/html
sudo echo-service start
How to LSBize an Init Script
A status page for dependency based boot sequencing is available.
This is a short documentation about how to make an Init Script LSB (Linux Standard Base)-compliant based on the Chapter 20 of the LSB 3.1.
LSB-compliant init scripts need to:
- provide, at least, the following actions: start, stop, restart, force-reload, and status. All of those, except for status, are required by the Debian Policy, chapter 9.3.2 Writing the scripts. "Status" support has been requested into policy, see #291148 and LSBInitScripts/StatusSupport.
- return proper exit status codes.
- document runtime dependencies.
- [optionally] Log messages using the Init.d functions: log_success_msg, log_failure_msg and log_warning_msg (This would introduce consistent output in scripts, as requested in http://lists.debian.org/debian-devel/2005/06/msg00729.html
and should also follow Debian Policy, chapter 9.4 Console messages from init.d scripts)
Full information on the actions (and return codes) that LSB scripts have to honor are available at LSB 3.1, Chapter 20.2. Init Script Actions. Maintainers should review that section and review / adjust their init.d scripts accordingly.
Run-time dependencies
Adding run-time dependencies was a release goal for Lenny, and dependency based boot sequencing is the default in Squeeze. There is a separate wiki page documenting that effort.
By documenting the run-time dependencies for init.d scripts, it becomes possible to verify the current boot order, order the boot using these dependencies, and run boot scripts in parallel to speed up the boot process.
Add a block like this in the init.d script:
### BEGIN INIT INFO
# Provides: scriptname
# Required-Start: $remote_fs $syslog
# Required-Stop: $remote_fs $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Start daemon at boot time
# Description: Enable service provided by daemon.
### END INIT INFOThe block shown above has a special rigid format delimited by the lines
### BEGIN INIT INFO
### END INIT INFOwhere all trailing spaces shall be ignored. On the other hand, all lines inside the block shall be of the form
# {keyword}: arg1 [arg2...]and begin with a hash character '#' in the first column followed by one single space, except for the lines following the Description keyword. The following keywords are defined
Provides: boot_facility_1 [boot_facility_2...]
- defines boot facilities provided by this init script such that when the script is run with the start argument, the specified boot facilities will be deemed present and hence other init scripts which require those boot facilities must be started at a later stage. Normally you should use the script name as boot facility (without .sh if the file name has such an ending) but one can in the exceptional case also use the name of the service(s) that the script replaces. Boot facilities provided by scripts must not start with '$'. (Virtual facility names listed below are defined outside the init.d scripts.) Facility names should be unique within the distribution, to avoid 'duplicate provides' errors when a package is installed.
Required-Start: boot_facility_1 [boot_facility_2...]
- defines facilities that must be available to start the script. Consider using virtual facility names as described below if adequate. If no boot facility is specified it means that this script can be started just after the bootstrap without local filesystems mounted, nor system logger, etc.
Required-Stop: boot_facility_1 [boot_facility_2...]
- defines facilities used by the service provided by the script. The facility provided by this script should stop before the listed facilities are stopped to avoid conflicts. Normally you would include here the same facilities as for the Required-Start keyword.
Should-Start: boot_facility_1 [boot_facility_2...]
- defines the facilities that if present should start before the service provided by the script. Nevertheless, the script can still start if the listed facilities are missing. This allows for weak dependencies which do not cause the service to fail if a facility is not available. Consider using virtual facility names as described below if adequate.
Should-Stop: boot_facility_1 [boot_facility_2...]
- defines the facilities that if present should be stopped after this service. Normally you would include here the same facilities as those used with the Should-Start keyword.
Default-Start: run_level_1 [run_level_2...]
Default-Stop: run_level_1 [run_level_2...]
- defines the run levels where the script should be started (stopped) by default. For example, if a service should run in runlevels 3, 4, and 5 only, specify "Default-Start: 3 4 5" and "Default-Stop: 0 1 2 6".
Short-Description: short_description
- provide a brief description of the actions of the init script. Limited to a single line of text.
Description: multiline_description
- provide a more complete description of the actions of the init script. May span multiple lines. In a multiline description, each continuation line shall begin with a '#' followed by tab character or a '#' followed by at least two space characters. The multiline description is terminated by the first line that does not match this criteria.
X-Start-Before: boot_facility_1 [boot_facility_2...]
X-Stop-After: boot_facility_1 [boot_facility_2...]
- provide reverse dependencies, that appear as if the listed facilities had should-start and should-stop on the package with these headers.
X-Interactive: true
- Indicates that this init script can interact with the user, requesting some input (for example, a password). This make sure the script run alone when the boot system starts scripts in parallell and have direct access to the tty.
For dependency tracking, the provides, required- and should- keywords are important, and the rest is unused. The default runlevels are used by a program to order the init scripts (e.g.
insserv
) to keep track of which rc#.d directory to update when a service is added for the first time, and should reflect the intent of the service.
There are some "virtual" facility names, listed in the [LSB 3.1]. These are:
| $local_fs | all local filesystems are mounted. All scripts that write in /var/ need to depend on this, unless they already depend on $remote_fs. |
| $network | low level networking (ethernet card; may imply PCMCIA running) |
| $named | daemons which may provide hostname resolution (if present) are running. For example, daemons to query DNS, NIS+, or LDAP. |
| $portmap | daemons providing ?SunRPC/ONCRPC portmapping service as defined in RFC 1833 (if present) are running all remote |
| $remote_fs | all filesystems are mounted. In some LSB run-time environments, filesystems such as /usr may be remote. If the script need a mounted /usr/, it needs to depend on $remote_fs. Scripts depending on $remote_fs do not need to depend on $local_fs. During shutdown, scripts that need to run before sendsigs kills all processes should depend on $remote_fs. |
| $syslog | system logger is operational |
| $time | the system time has been set, for example by using a network-based time program such as ntp or rdate, or via the hardware Real Time Clock. Note that just depending on ntp will not result in an accurate time just after ntp started. It usually takes minutes until ntp actually adjusts the time. Also note that standard insserv.conf just lists hwclock as $time. |
| $all | facility supported by insserv to start a script after all the scripts not depending on $all, at the end of the boot sequence. This only work for start ordering, not stop ordering. Depending on a script depending on $all will give incorrect ordering, as the script depending on $all will be started after the script depending on it. |
Other (non-system) facilities may be defined by other applications. These facilities shall be named using the same conventions defined for naming init scripts. See the list of proposed Debian specific virtual facilities for more information on this.
Most of this section was originally based from a message by Petter Reinholdtsen on Debian-devel.
BTS reports related to LSB headers are usertagged.
'Web > Server' 카테고리의 다른 글
| 스크립트 포멧 오류가 날 때 확인 (0) | 2018.02.20 |
|---|---|
| 웹서버 설정(apache2, php, mariadb) (0) | 2018.02.20 |
| 웹폴더 권한 설정 (0) | 2018.02.20 |
The ^M is a carriage return character. Linux uses the line feed character to mark the end of a line, whereas Windows uses the two-character sequence CR LF. Your file has Windows line endings, which is confusing Linux.
Remove the spurious CR characters. You can do it with the following command:
sed -i -e 's/\r$//' custom_script.sh'Web > Server' 카테고리의 다른 글
| 데몬 스크립트 작성 및 등록하기 (0) | 2018.02.21 |
|---|---|
| 웹서버 설정(apache2, php, mariadb) (0) | 2018.02.20 |
| 웹폴더 권한 설정 (0) | 2018.02.20 |
[아파치 설치]
apt-get install apache2
#a2enmod rewrite #a2enmod headers #a2enmod ssl #a2dismod -f autoindex
vi /etc/apache2/apache2.conf
# deny (log file, binary, certificate, shell script, sql dump file) access.<FilesMatch "\.(?i:log|binary|pem|enc|crt|conf|cnf|sql|sh|key)$"> Require all denied</FilesMatch> # deny access.<FilesMatch "(?i:composer\.json|contributing\.md|license\.txt|readme\.rst|readme\.md|readme\.txt|copyright|artisan|gulpfile\.js|package\.json|phpunit\.xml)$"> Require all denied</FilesMatch># Allow Lets Encrypt Domain Validation Program<DirectoryMatch "\.well-known/acme-challenge/"> Require all granted</DirectoryMatch>
[PHP 설치]
apt-get install php
apt-get install libapache2-mod-php
apt-get install php-mcrypt
apt-get install php-mbstring
apt-get install php-gd
apt-get install php-curl php-xml
apt-get install php-mysql php-mongodb
apt-get install libapache2-mpm-itk
vi /etc/php/7.0/apache2/php.ini 에 아래 두줄 추가
extension=mongodb.so
extension=mysqli.so
- 설정
vi /etc/apache2/mods-available/php7.0.conf
<FilesMatch ".+\.ph(p3|p4|p5|p7|t|tml)$"> Require all denied</FilesMatch>
vi /etc/php/7.0/apache2/php.inivi /etc/php/7.0/cli/php.ini
date.timezone = Asia/Seoul
/etc/init.d/apache2 restart
[MariaDB 설치]
apt-get install mariadb-server
/usr/bin/mysql_secure_installation
mysql
use mysql; update user set plugin='' where User='root'; flush privileges; exit;
비밀번호가 틀렸다면
use mysql;
SET PASSWORD FOR 'root'@'localhost'=PASSWORD('비밀번호');
exit;
SET PASSWORD FOR 'root'@'localhost'=PASSWORD('turtle123');
-언어설정 추가 (중요)
vi /etc/mysql/mariadb.conf.d/50-server.cnf
character-set-server = utf8mb4collation-server = utf8mb4_unicode_ci/etc/init.d/mysql restart
이거 안했다고 route가 제대로 안되네...
/etc/apache2/sites-available/yoursite.conf
<VirtualHost *:80>
ServerAdmin youremail@yahoo.com
ServerName yoursite.com
ServerAlias www.yoursite.com
DocumentRoot "/var/www/yoursite.com/public"
<Directory /var/www/yoursite.com/public>
Options Indexes FollowSymLinks MultiViews
AllowOverride All
Order allow,deny
allow from all
</Directory>
</VirtualHost>SSL 설정
웹사이트 Apache 환경설정파일 작성
#16.12.20 설정 가이드가 추가됨
환경설정을 쉽게하도록 도와주는, 환경설정 생성기가 추가되었습니다.
https://blog.lael.be/demo-generator/apache/my-example-site.com.php
다음의 내용을 작성한다.
아래 예제에서는 사이트 환경설정파일명을 lael.be 로 가정하고 진행한다.
당신의 도메인, 사용자 아이디, 별도의 구분단어로 설정해서 사용하도록 하자.
#vi /etc/apache2/sites-available/lael.be.conf
/etc/apache2/sites-available/lael.be.conf 에 저장한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | <VirtualHost *:80> #main domain ServerName lael.be #additional domain ServerAlias www.lael.be ServerAlias my-anotherdomain.com #document Root DocumentRoot /home/myuser1/www/ #additional setting <Directory /home/myuser1/www/> Options FollowSymLinks MultiViews AllowOverride All require all granted </Directory> AssignUserID myuser1 myuser1 ErrorLog ${APACHE_LOG_DIR}/lael.be-error.log CustomLog ${APACHE_LOG_DIR}/lael.be-access.log combined</VirtualHost> |
ServerAlias 는 사용안하면 빼도 되는 줄이다.
#15.09.16 추가
당신이 만약 SSL(https) 를 적용하고자 한다면 lael.be.conf 파일 하단에 다음의 코드를 추가하세요. 즉 VirtualHost 영역을 하나 더 추가.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | <VirtualHost *:443> #main domain ServerName lael.be #additional domain ServerAlias www.lael.be ServerAlias my-anotherdomain.com #document Root DocumentRoot /home/myuser1/www/ #additional setting <Directory /home/myuser1/www/> Options FollowSymLinks MultiViews AllowOverride All require all granted </Directory> AssignUserID myuser1 myuser1 ErrorLog ${APACHE_LOG_DIR}/lael.be-error.log CustomLog ${APACHE_LOG_DIR}/lael.be-access.log combined Header always set Strict-Transport-Security "max-age=31536000" SSLEngine on SSLProtocol all -SSLv2 -SSLv3 SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA SSLHonorCipherOrder on SSLCertificateFile "/home/myuser1/ssl/mysite_ssl.crt" SSLCertificateKeyFile "/home/myuser1/ssl/mysite_ssl.key" SSLCertificateChainFile "/home/myuser1/ssl/mysite_ssl.certchain.crt"</VirtualHost> |
https://www.sslshopper.com/ssl-checker.html#hostname=blog.lael.be (SSL Chain test - 인증서가 올바르게 설치되어 있는지)
https://www.ssllabs.com/ssltest/analyze.html?d=blog.lael.be (SSL Algorithm test - 안전한 암호화 통신이 설정되어 있는지)
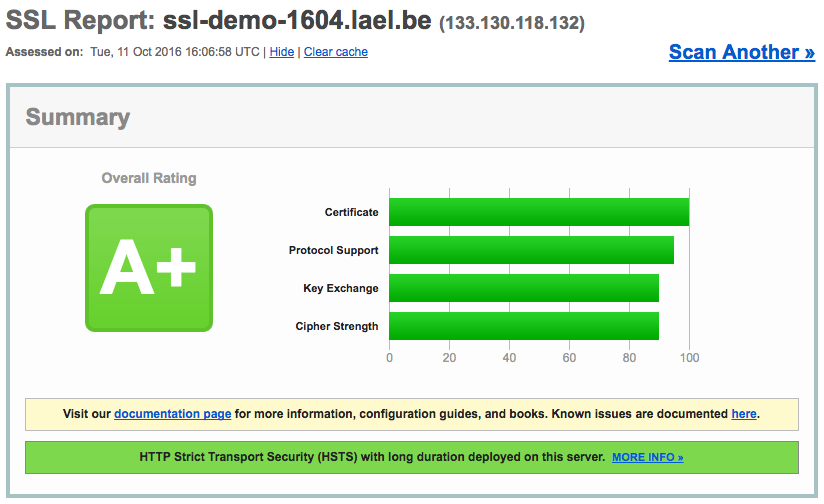
Chain test 는 모두 Valid 이어야하고, SSL Algorithm test 는 A 이상이면 정상적인 운영이 가능하다.
라엘이가 여러 설정 값에 대해서 테스트를 해 보았고, 최적의 권장설정 값을 위와 같이 적어두었으니 그대로 쓰면 된다.
위의 설정값으로 SSL을 설치하면 A+등급을 받을 수 있을 것이다.
.
인증서 적용 테스트는 위의 사이트를 이용하여라.
인증서 체인 파일이란 “인증서에 대한 인증서” 파일이다.
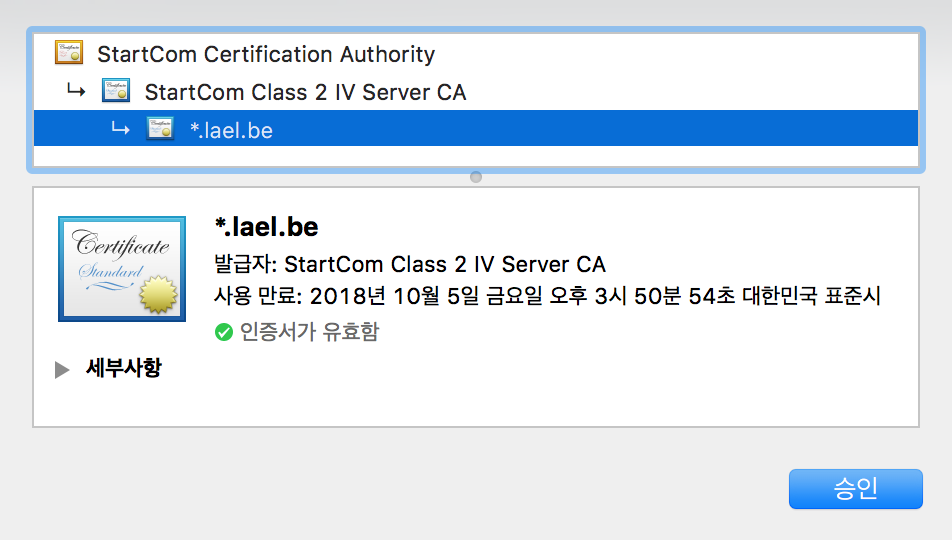
< 그림 : 이 블로그는 위의 단계를 거쳐 인증된다. 이것을 체인 인증 이라고 한다. >
대통령이 당신을 인증할 때 직권으로 인증하는 것이 아니라, 대통령 -> 서울시장 -> 강남구청장 -> 삼성동장 -> 당신 의 단계를 거친다. 검증하려면 모든 단계의 보증 증서를 제공해야 하는 것이다.
인증서 파일에는 삼성동장 -> 당신 의 정보가 들어있고, (암호화 통신시 공개됨)
인증서 키 파일에는 암호화 통신을 위한 정보가 들어있고 (은행 보안카드 로 비유. 외부에 공개되지 않음.)
인증서 체인 파일에는 대통령 -> 서울시장, 서울시장 -> 강남구청장, 강남구청장 -> 삼성동장 의 정보가 들어있다. (체인 인증이라고 한다. 연결고리 인증)
인증서 체인을 올바르게 작성하지 않으면 Firefox 브라우저와 Android Chrome 브라우저에서 “인증서 정보부족” 오류가 발생하게 된다.
14) 사이트 활성화 및 적용
명령어는
#a2ensite 사이트환경설정파일명
입니다.
#a2ensite lael.be
(참고로 사이트 비활성화는
#a2dissite lael.be
입니다.)
- 아파치 설정 다시 불러오기(적용을 위해)
#service apache2 reload
참조: https://blog.lael.be/post/73
'Web > Server' 카테고리의 다른 글
| 데몬 스크립트 작성 및 등록하기 (0) | 2018.02.21 |
|---|---|
| 스크립트 포멧 오류가 날 때 확인 (0) | 2018.02.20 |
| 웹폴더 권한 설정 (0) | 2018.02.20 |
폴더 권한 때문에 웹페이지를 제대로 띄우지 못하는 경우가 있다.
권한을 제대로 설정해야한다.
웹서비스의 홈디렉토리의 소유자를 www-data:www-data 로 변경하는 방법이 있다.
BASH
sudo chown -R www-data:www-data /home/unclepapa/public_html
위와 같은 방식은 www-data의 권한을 탈취당해도 www-data가 가진 권한이 매우 적기에 보안상 추천되고 있다. 하지만 이는 FTP 접속에 제한이 될 수 밖에 없는데 계정사용자가 홈디렉토리에 접속해도 소유권이 모두 www-data 이기에 업로드/수정이 불가능하게 된다.
FTP 사용에 편의를 위해서는 어떻게든 디렉토리와 파일의 소유권이 계정사용자를 포함해야 하는데, Owner 값은 id 값으로 중복될 수 없기때문에 www-data 값을 변경할 수는 없다.
Group 값은 중복될 수 있기때문에 www-data의 group에 FTP 계정을 사용할 사용자를 추가할 수 있다.
BASH
sudo usermod -a -G www-data unclepapa
이 경우 기본적인 리눅스 umask 값에 의해 디렉토리 퍼미션이 755이기에 umask 값을 002로 변경하여 생성하는 디렉토리나 파일들이 775 / 664의 값을 갖도록 해야 파일의 업로드/수정이 가능해진다.
BASH
sudo chmod -R 775 /home/unclepapa/public_html
혹은 umask 값을 수정( 특정사용자의 umask 값을 변경하려면 ~/.bashrc 에 값을 적용)
BASH
sudo vi /etc/profile
umask 002
출처: http://webdir.tistory.com/231 [WEBDIR]
'Web > Server' 카테고리의 다른 글
| 데몬 스크립트 작성 및 등록하기 (0) | 2018.02.21 |
|---|---|
| 스크립트 포멧 오류가 날 때 확인 (0) | 2018.02.20 |
| 웹서버 설정(apache2, php, mariadb) (0) | 2018.02.20 |
입력창-regedit
HKEY_CLASSES_ROOT\Excel.Sheet.8\shell\Open
HKEY_CLASSES_ROOT\Excel.Sheet.12\shell\Open
백업 후 삭제
editor를 사용하여 각각 입력 후 .reg로 저장 후 실행.
끝.
HKEY_CLASSES_ROOT\Excel.Sheet.8\shell\Open
HKEY_CLASSES_ROOT\Excel.Sheet.12\shell\Open
백업 후 삭제
editor를 사용하여 각각 입력 후 .reg로 저장 후 실행.
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\Excel.Sheet.8\shell\Open]
@="열기(&O)"
[HKEY_CLASSES_ROOT\Excel.Sheet.8\shell\Open\command]
@="\"C:\\Program Files\\Microsoft Office\\Office12\\EXCEL.EXE\" /m \"%1\""
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\Excel.Sheet.12\shell\Open]
@="열기(&O)"
[HKEY_CLASSES_ROOT\Excel.Sheet.12\shell\Open\command]
@="\"C:\\Program Files\\Microsoft Office\\Office12\\EXCEL.EXE\" /m \"%1\""
끝.
'etc' 카테고리의 다른 글
| xcopy 통째로 복사 (0) | 2020.09.16 |
|---|---|
| popJazzSmooth (0) | 2010.11.17 |
| 깡통파일(더미파일) 만들기 (0) | 2010.09.01 |
| Source Insight 3.5 떠있는 창 10개로 제한하기 (0) | 2010.07.09 |
| SourceInsight 한글 주석 깨지지 않게하기 (0) | 2010.07.09 |
find 상위디렉토리 type d -name "파일명" -exec rm -rf {} \;
'old > Linux' 카테고리의 다른 글
| 심볼릭링크 생성 (0) | 2010.08.13 |
|---|---|
| smb.conf 설정 예 (0) | 2010.08.10 |
| 일정 등록(자동 종료 등) - cron (0) | 2010.05.11 |
| 지정 시간에 동작을 예약하는 명령어 [at 사용법] (0) | 2010.05.08 |
| 리눅스용 소스 비교 툴 (0) | 2010.04.19 |

통쾌한 액션인 줄만 알고 보기 시작한 'Sucker Punch'.
절망적인 현실을 벗어나고자 했던 용기있는 한 소녀의 이야기를 왜곡된 현실과 비현실적인 공간에서의 판타지 액션으로 표현한 영화이다.
도입부분에 우리를 돕는 천사의 존재를 언급하며 그 존재는 악마로라도 나타나 우리에게 이야기할 거라고 말하는데... 그 천사라는 존재는 웬 중년 아저씨의 모습으로 소녀를 너무 적나라하게 돕는다;;;
영화를 보는 내내 천사를 언급했었던 이유가 단지 쌩뚱맞게 등장하는 그 이상한 아저씨의 존재를 정당화 시키기 위한 수단이라고 생각했다.
하지만 이 마지막 나레이션이 영화가 표현하고자 했던 것이 무엇인지 다시 한번 깊이 생각하게 하였다.
And finally, this question:
The mystery of whose story it will be...
...of who draws the curtain.
Who is it that chooses our steps in the dance?
Who drives us mad...
...lashes us with whips...
...and crowns us with victory when we survive the impossible?
Who is it... that does all these things?
Who honors those we love with the very life we live?
Who sends monsters to kill us... and at the same time sings that we'll never die?
Who teaches us what's real and how to laugh at lies?
Who decides why we live and what we'll die to defend?
Who chains us?
And who holds the key that can set us free?
It's you.
You have all the weapons you need.
Now fight.
주님의 계획으로 시작된 우리의 삶이 고단하고 힘들 수도 있겠지만 감당할만한 시험을 주사 능히 피할 길을 내시는 주님께서 우리를 응원하고 계시기에 구원의 확신을 가지고 우리 인생의 경주를 힘써 이겨나가야 한다는 도전의 메세지를 던져주고 있는 것이 아닐까?
'old > Facebook' 카테고리의 다른 글
| 우산 속의 그녀(?) (0) | 2011.07.11 |
|---|
 itistory-photo-1
itistory-photo-1출근 길에 멍하니 걸어가다 앞서 가는 아가씨가 입고있는 후드티에 새겨진 깜찍한 그림이 비가 억수같이 쏟아지는 오늘 아침의 날씨와 너무나 잘 어울리는 것 같아 피식 웃음이 나왔다. 왠지 그 옷을 입은 아가씨도 깜직할 거 같다는 생각이 들어 설레기도 했다.
옷에 새겨진 작은 그림 하나로도 그 옷을 입은 사람에 대한 호감도를 Up! 시켜주는 것을 보면 처음 만나는 누군가에게 좋은 인상을 남겨주기 위해서는 평소에 잘 하고 다녀야 겠다는 생각이 든다.
iPhone 에서 작성된 글입니다.
'old > Facebook' 카테고리의 다른 글
| 모래속 진주같은 영화, Sucker Punch (0) | 2011.08.14 |
|---|
[전체 과정]
1. 하드를 장착한다.
2. 장착한 하드의 파티션을 나누고 포멧한다.
3. /etc/fstab에 등록하여 마운트 한다.
[세부 과정]
- 파티션 나누기
- gui 환경에서 gparted 어플리케이션을 이용하기
$ sudo apt-get install gparted
시스템->관리->파티션편집기 실행
- shell 환경에서 파티션 나누기
1) dmesg란 명령어를 사용하여 장착된 SCSI HDD의 정보를 확인한다
2nd SCSI drive라면 sdb* 라는 mount id로 접속 될테니 아래와 같이 확인한다.
$ dmesg | grep sdb*
2) fdisk로 파티션 나누기 (/dev/sdb라고 가정)
$ fdisk /dev/sdb
(귀찮다. 알아서 해라 ㅡ_ㅡ;)
3) 포멧하기 (ext4 파일시스템의 경우)
$ mke2fs -t ext3 /dev/sdb
4) 마운트 시킬 디렉토리를 만들자
$ mkdir home2
5) 마운트 시켜보자
$ mount -t ext4 /dev/sdb /home2
마운트 된 것을 확인한다.
$ df -h
6) 부팅될 때 마운트되게 하기 위해서 /etc/fstab에 추가한다.
- 마운트 시킬 하드드라이브의 UUID를 확인하자.
$ sudo blkid
대략 이렇게 출력된다.
"/dev/sdb4: UUID="f80df0b7-6444-447e-a5ff-5c68a4e67250" TYPE="ext4""
출력되는 내용의 UUID를 복사하여 fstab에 등록한다.
$ sudo vi /etc/fstab
추가할 내용은 아래와 같다.
아래와 같은 UUID를 가지는 ext4 파티션을 /home2 폴더로 마운트한다는 내용이다.
# /home2 was on /dev/sdb4 second hard disk drive
UUID=f80df0b7-6444-447e-a5ff-5c68a4e67250 /home2 ext4 defaults 0 2
재부팅해서 되면 성공.
'Web > Ubuntu' 카테고리의 다른 글
| hostname 변경 (0) | 2011.02.19 |
|---|---|
| iso 이미지 만들기, cd 굽기 (0) | 2011.02.12 |
| [error] E: Sub-process /usr/bin/dpkg returned an error code (1) (0) | 2011.01.26 |
| shell 한글 입력 (0) | 2010.11.12 |
| [error] setuid (0) | 2010.05.06 |
[hostname 변경]
1. hostname 명령을 사용해 현재 값 확인
2. /etc/hostname의 값을 변경
3. hostname -F /etc/hostname
4. 새로운 터미널을 열어 확인
[hosts 변경]
1. /etc/hosts에서 localhost name을 확인한다.
2. localhost name을 위에서 변경한 name으로 변경한다.
1. hostname 명령을 사용해 현재 값 확인
2. /etc/hostname의 값을 변경
3. hostname -F /etc/hostname
4. 새로운 터미널을 열어 확인
[hosts 변경]
1. /etc/hosts에서 localhost name을 확인한다.
2. localhost name을 위에서 변경한 name으로 변경한다.
'Web > Ubuntu' 카테고리의 다른 글
| 하드 추가 장착 및 자동 마운트 (0) | 2011.02.19 |
|---|---|
| iso 이미지 만들기, cd 굽기 (0) | 2011.02.12 |
| [error] E: Sub-process /usr/bin/dpkg returned an error code (1) (0) | 2011.01.26 |
| shell 한글 입력 (0) | 2010.11.12 |
| [error] setuid (0) | 2010.05.06 |
big-endian and little-endian
|
빅 엔디안과 리틀 엔디안은 컴퓨터 메모리에 저장된 바이트들의 순서를 설명하는 용어이다. 빅 엔디안은 큰 쪽 (바이트 열에서 가장 큰 값)이 먼저 저장되는 순서이며, 리틀 엔디안은 작은 쪽 (바이트 열에서 가장 작은 값)이 먼저 저장되는 순서이다. 예를 들면, 빅 엔디안 컴퓨터에서는 16진수 "4F52"를 저장공간에 "4F52"라고 저장할 것이다 (만약 4F가 1000번지에 저장되었다면, 52는 1001번지에 저장될 것이다). 반면에, 리틀 엔디안 시스템에서 이것은 "524F"와 같이 저장될 것이다. IBM 370 컴퓨터와 대부분의 RISC 기반의 컴퓨터들, 그리고 모토로라 마이크로프로세서는 빅 엔디안 방식을 사용한다. 왼쪽에서 오른쪽으로 읽는 언어를 사용하는 사람들에게, 이것은 일련의 문자나 숫자를 저장하는 데 있어 자연스러운 방식이다. 한편, 인텔 프로세서나 DEC의 알파 프로세서, 그리고 적어도 그것들 상에서 운영되는 일부 프로그램들은 리틀 엔디안을 사용한다. 리틀 엔디안 순서에 대한 논리는, 수의 값을 증가시킬 때 수의 왼편에 자릿수를 추가해야할 필요가 있을지 모른다는 것이다 (지수가 아닌 경우에, 더 큰 숫자는 더 많은 자릿수를 갖는다). 빅 엔디안으로 정렬되어 저장되어 있는 숫자는 두 숫자를 더한 결과를 저장하기 위해 모든 자릿수를 오른쪽으로 옮겨야하는 일이 종종 발생한다. 그러나 리틀 엔디안 방식으로 저장된 숫자에서는, 최소 바이트가 원래 있던 자리에 그대로 머물 수 있으며, 새로운 자리 수는 최대 수가 있는 주소의 오른쪽에 추가될 수 있다. 이것은 일부 컴퓨터 연산들이 매우 단순해지고 빠르게 수행될 수 있다는 것을 의미한다. 자바나 FORTRAN과 같은 컴파일러들은 그들이 개발하는 목적 코드가 어떤 방식으로 저장될 것인지를 알아야만 한다. 필요한 경우, 한 방식에서 다른 방식으로 변경하는데 변환기가 사용될 수도 있다. |
|
바이트 순서가 빅 엔디안이든 리틀 엔디안 이든, 각 바이트 내에 들어있는 비트들은 둘 모두 빅 엔디안으로 정렬되어 있다는 데에 유의하라. 즉, 저장된 바이트의 주어진 숫자에 의해 표현되는 전체적인 비트 스트림에 관해서는 빅이나 리틀 엔디안으로 하려는 시도가 없다는 것이다. 예를 들어 16진수 4F가 저장공간 내에 주어진 저장 주소범위 내에 있는 다른 바이트들과 함께 처음에 저장되든 또는 나중에 저장되든 간에, 그 바이트 내의 비트 순서는 다음과 같을 것이다.
01001111
비트 순서에 대해서도 빅 엔디안이나 리틀 엔디안으로 구현하는 것이 가능하긴 하지만, 거의 모든 CPU나 프로그램들은 빅 엔디안 비트 순서로 설계된다. 그러나 데이터 통신에서는, 비트 순서를 둘 중 어느 한쪽으로 하는 것이 가능하다.
에릭 레이몬드는 인터넷 도메인 이름과 전자우편 주소들이 리틀 엔디안 방식으로 표현된 것이라고 말한다. 예를 들어 만약, 텀즈 사이트의 주소를 빅 엔디안 방식으로 쓴다면 다음과 같은 형식을 가질 것이다.
kr.co.terms.www
빅 엔디안과 리틀 엔디안이라는 용어는 조나단 스위프트의 걸리버 여행기로부터 파생되었다.
[펌 '김동근의 텀즈']
'old > 용어정리' 카테고리의 다른 글
| OSI (Open Systems Interconnection) ; 개방형 시스템간 상호 접속 (0) | 2010.11.18 |
|---|---|
| layer and layering ; 계층, 계층화 (0) | 2010.11.18 |
| Jolt (0) | 2010.11.18 |
| IT (information technology) ; 정보기술 (0) | 2010.11.18 |
| ISV (independent software vendor) (0) | 2010.11.18 |
- 굽고자 하는 데이터를 raw데이터로
# mkisofs -o cdimage.iso -J -V Testiso -x/home/etc /home/backup_data
CD로 굽기 전에 raw 데이터가 제대로 만들어졌는지 mount를 통해서 확인한다.
-o: 생성될 ISO 이미지 파일 이름
-J: 윈도우즈 호환 Joliet Filesystem으로 64자의 파일이름을 허용
-V: Volume ID 생성
-x: 이 옵션 다음에 나오는 디렉토리는 즉시 제외, 반복사용가능
ex) $ mkisofs -o Ports_Build.iso -J -V Ports_Build /source/export/20081212.1.0.5.7-56.CC/
mkisofs -o Src.iso -J -R -A Src -V Src -v -x/source/export/2001212.1.0.5.7-56.CC/Ports /source/export/20081212.1.0.5.7-56.CC/
$ mkdir /mnt/testiso
$ mount cdimage.raw -r -t iso9660 -o loop /mnt/testiso
scanbus 옵션을 이용해서 장치버스를 찾아낸다.
# cdrecord -scanbus
Cdrecord 1.10 (i686-pc-linux-gnu) Copyright (C) 1995-2001 Jrg Schilling
Linux sg driver version: 3.1.20
Using libscg version 'schily-0.5'
scsibus0:
0,0,0 0) 'PLEXTOR ' 'CD-R PX-W1210A' '1.08' Removable CD-ROM
0,1,0 1) *
0,2,0 2) *
0,3,0 3) *
...
이제 굽는다.
위의 dev에 들어가는 값은 scanbus로 찾아낸 값이다.
#> cdrecord -v -eject speed=8 dev=0,0,0 -data cdimage.iso(cdimage.raw)
- dev 구조: dev= scsibus, target, lun [ dev=1,0 or dev=0,1,0 ]
( 대개 scsibus는 0번이며 , 이경우 그냥 target 과 lun 부분만을 적어도 됨.)
- target : 자기 레코더의 ID 번호
( 조회방법: cdrecord -scanbus 또는 eject /dev/scd0 )
-v : 레코딩 정보를 상세 출력
-eject : 레코딩 후 디스크 배출
speed=x : 레코딩 배속
- dev 구조: dev= scsibus, target, lun [ dev=1,0 or dev=0,1,0 ]
( 대개 scsibus는 0번이며 , 이경우 그냥 target 과 lun 부분만을 적어도 됨.)
- target : 자기 레코더의 ID 번호
( 조회방법: cdrecord -scanbus 또는 eject /dev/scd0 )
-v : 레코딩 정보를 상세 출력
-eject : 레코딩 후 디스크 배출
speed=x : 레코딩 배속
USD RW를 사용했더니 dev=7,0,0
#> cdrecord -v eject speed=8 dev=7,0,0 -data cdimage.iso
시디가 정말로 제대로 구워졌는지 mount시켜서 한번 확인해 보도록 하자.
# mount /dev/scd0 /mnt/cdrom[출처] Linux에서 CD 굽기|작성자 나니
'Web > Ubuntu' 카테고리의 다른 글
| 하드 추가 장착 및 자동 마운트 (0) | 2011.02.19 |
|---|---|
| hostname 변경 (0) | 2011.02.19 |
| [error] E: Sub-process /usr/bin/dpkg returned an error code (1) (0) | 2011.01.26 |
| shell 한글 입력 (0) | 2010.11.12 |
| [error] setuid (0) | 2010.05.06 |
apt-get으로 패키지를 설치할 때 패키지가 깨지거나 하는 등의 문제로 아래의 에러를 내며 설치가 되지 않는 경우가 종종 생긴다.
E: Sub-process /usr/bin/dpkg returned an error code (1)
아래는 설치하려는 패키지의 파일이 다른 패키지에도 포함되어 있어 덮어씌우기를 해야하는 상황이다.
이럴 땐 패키지 파일이 있는 디렉토리로 이동해 아래처럼 강제로 덮어씌우는 옵션을 줘서 설치한다.
root@ubuntu:/var/cache/apt/archives# dpkg -i --force-overwrite 패키지명
'Web > Ubuntu' 카테고리의 다른 글
| hostname 변경 (0) | 2011.02.19 |
|---|---|
| iso 이미지 만들기, cd 굽기 (0) | 2011.02.12 |
| shell 한글 입력 (0) | 2010.11.12 |
| [error] setuid (0) | 2010.05.06 |
| 싱글모드 부팅 (0) | 2010.05.06 |
Public key 생성
$ ssh-keygen –t rsa
$ cat ~/.ssh/id_rsa.pub
내용을 복사한다.
git.lge.com에서 gerrit을 방문한다.
위 과정을 완료 했으면 ~/.ssh/known_hosts에 복사한 host key를 붙여넣는다.
$ vi ~/.ssh/known_hosts
$ git config --global user.name “Your AD Account”
$ git config --global user.email “Your E-mail”
$ git config --global merge.tool kdiff3
- Public key Check
$ ssh -p 29468 165.243.137.26
$ cd ~
$ mkdir bin
$ curl http://android.git.kernel.org/repo > ~/bin/repo
$ chmod a+x ~/bin/repo
$ mkdir p500_gingerbread
$ cd p500_gingerbread.
$ repo init -u ssh://YourADAccount@165.243.137.26:29468/p500_gingerbread/manifest.git -b p500_gingerbread_master
$ repo sync
$ repo start p500_gingerbread_master –all
'old > Git' 카테고리의 다른 글
| git 작업취소 (0) | 2010.08.07 |
|---|---|
| git 요약 (0) | 2010.07.27 |
| Subversion Git 사용법 (0) | 2010.05.14 |
| Eclipse Plugins (0) | 2010.02.01 |
| Git과 SVN 통합 (0) | 2010.02.01 |
1. 수학 함수
1) 표준 함수
5) 절대값 함수
3) 기타 시간 함수
1) 표준 함수
C컴파일러는 많은 수의 표준 함수들을 제공한다. 공통적으로 자주 사용되는 기능들을 모든 개발자들이 직접 만들어 쓴다면 시간도 많이 걸릴 것이고 사회적인 낭비도 심할 것이다. 모든 개발자들이 화면 입출력을 위해 printf, scanf 같은 함수를 일일이 만들어 써야 한다면 얼마나 끔찍하겠는가? 이런 함수들의 기능은 워낙 뻔하기 때문에 누가 만들어도 비슷한 모양을 가질 것이며 어떤 특수하고도 고유한 기능을 요구하는 것도 아니다.
표준은 필요한 함수의 최소한의 목록만을 규정하며 컴파일러 제작사는 필요에 따라 함수를 더 추가로 정의할 수도 있다. 그래서 컴파일러 제작사에 따라 런타임 라이브러리의 구성이 조금씩 달라질 수 있으므로 약간의 주의를 기울일 필요는 있다. 예를 들어 터보 C에는 gotoxy, clrscr 함수들이 있지만 비주얼 C++에는 이 함수들이 없으며 같은 함수라도 이름이 조금씩 다른 경우도 있다. 하지만 printf, puts, getch 같은 기본적인 함수들은 대부분의 컴파일러에 공통적으로 존재하므로 컴파일러에 상관없이 자유롭게 사용할 수 있다. 표준 함수들은 기능에 따라 다음과 같이 분류할 수 있다.
|
분류 |
함수 |
|
입출력 함수 |
printf, scanf, gets, puts, getch, putch |
|
수학 함수 |
sin, cos, tan, pow, floor, ceil, hypot |
|
문자열 함수 |
strcpy, strlen, strcat, strstr, strchr |
|
시간 함수 |
time, asctime, clock |
|
파일 입출력 함수 |
fopen, fclose, fseek, fread, fwrite |
|
프로그램 제어 |
exit, abort, system |
|
메모리 할당 |
malloc, free, realloc, calloc |
|
기타 |
rand, delay |
2) 삼각 함수
수학 함수는 수학적인 계산을 하는 함수들이다. 수학 함수들의 원형은 모두 math.h에 선언되어 있으므로 이 함수들을 사용하려면 제일 먼저 #include <math.h> 전처리문을 삽입하여 이 헤더 파일을 포함시켜야 한다. 이 책에서 사용하는 Turboc.h가 이 헤더 파일을 포함하고 있지 않으므로 math.h를 포함하지 않으면 수학 함수를 쓸 수 없다. 실제 프로젝트를 할 때도 반드시 math.h를 인클루드해야 함을 꼭 기억해 놓도록 하자.
수학 함수 중에 비교적 이해하기 쉬운 삼각 함수에 대해 먼저 정리해 보자. 삼각 함수들은 이름만 다르고 원형이 모두 동일하다. 실수형 인수를 하나 받아들이며 이 인수의 삼각함수값을 계산하여 그 결과를 실수로 리턴한다.
double sin(double x);
double cos(double x);
double tan(double x);
double asin(double x);
double acos(double x);
double atan(double x);
double sinh(double x);
double cosh(double x);
double tanh(double x);
기본적인 수학 교육을 받았다면 sin, cos, tan 함수가 어떤 값을 계산한다는 것은 잘 알고 있을 것이다. asin, acos, atan 함수는 기본 삼각 함수의 역함수들이며 sinh, cosh, tanh는 쌍곡선 삼각함수라는 것이다. 설마 그럴리야 없겠지만 삼각 함수가 뭐하는 함수인지 모르겠다는 사람은 수학책을 참고하기 바란다. 이 책은 수학책이 아니므로 함수들이 구하는 값의 수학적 의미에 대한 설명은 하지 않기로 한다.
삼각 함수들이 받아들이는 인수 x는 360분법의 각도가 아니라 호도(라디안)값이다. 1호도는 원주의 길이가 반지름과 같아지는 각도인데 180/3.1416으로 정의되어 있다. 따라서 각도값으로 호도를 구할 때는 다음 공식을 사용하면 된다.
호도=각도*3.1416/180
sin(r*3.1416/180)
3) 지수 함수
지수 함수는 거듭승이나 제곱근, 로그 따위의 값을 구하는 함수들이다. 실수 차원에서 계산을 하므로 취하는 인수나 리턴값은 모두 정밀도가 높은 double 실수형이다. 다음과 같은 것들이 있다.
|
함수 |
설명 |
|
double sqrt(double x); |
x의 제곱근 |
|
double pow(double x,double y); |
xy. x의 y승 |
|
double log(double x); |
자연 대수 |
|
double log10(double x); |
상용 대수 |
|
double exp(double x); |
자연 대수 exp |
|
double hypot(double x,double y); |
직삼각형의 사변 길이 |
sqrt 함수는 제곱근, 즉 두 번 곱해서 그 값이 되는 수를 구한다. sqrt(4)의 결과는 2.0이 될 것이며 sqrt(2)는
log 함수는 로그값을 계산하고 log10은 밑이 10으로 고정되어 있는 상용 로그값을 구한다. 지수 함수 중에는 hypot 함수(Hypotenuse의 약자이다.)가 제일 어려운데 이 함수도 잘 알아두면 유용하게 쓰일 곳이 많다. hypot가 계산하는 값은 인수로 주어진 x와 y의 제곱의 합에 대한 양의 제곱근이다. 무척 복잡한 것 같지만 수식으로 표현해 보면
hypot(x,y)는 sqrt(pow(x,2)+pow(y,2))와 동일하며 조금 더 간단하게 쓴다면 sqrt(x*x+y*y)와 같다. 두 점의 좌표를 알고 있을 때 이 두 점간의 거리를 구하고 싶다면 hypot 함수를 사용한다. 예를 들어 한 점을 중심으로 하고 나머지 한 점까지를 반지름으로 하는 원을 그린다거나 할 때 이 함수가 필요할 것이다. 사용예를 보이고 싶으나 콘솔 환경에서는 그래픽을 그릴 수 없으므로 다음에 그래픽을 배우면 그때 직접 실습해 보기 바란다.
요즘은 컴퓨터라는 기계가 게임도 하고 인터넷도 하고 영화도 보고 다양한 용도로 활용되고 있지만 원래 컴퓨터는 수학적인 계산을 위해 만들어진 것이다. 그래서 프로그래밍은 수학과 아주 밀접한 연관이 있는데 간단한 프로그램은 사칙 연산으로도 원하는 대부분의 계산을 할 수 있지만 조금만 복잡해지면 고등 수학이 필요해진다.
4) 정수화 함수
정수화 함수는 실수형 데이터에서 정수부만을 취하는, 즉 소수점 이하의 소수부를 잘라 버리는 함수이다. 소수부를 잘라 버린다고 해서 계산 결과가 정수가 되는 것은 아니며 리턴값은 여전히 실수이다. 실수값의 소수부만을 0으로 만든다고 생각하면 된다. 정수화 함수에는 다음 두 가지가 있다.
double floor( double x );
double ceil( double x );
두 함수는 소수점 이하를 자르는 방식이 다른데 floor는 소수점 이하를 버리고 정수부만을 취하고 ceil은 소수점 이하를 올림해서 정수부를 1증가시킨다. 다음 호출 예를 보면 쉽게 이해가 될 것이다.
floor(3.14); // 결과는 3.0
ceil(3.14) // 결과는 4.0
floor는 내림을 하는 함수이고 ceil은 올림을 하는 함수라고 일단 정리할 수 있다. 그러나 단순히 내림, 올림으로 이 두 함수의 동작을 정의하는 것은 정확하지 않다. 다음 예를 보자.
floor(-3.14); // 결과는 -4.0
ceil(-3.14) // 결과는 -3.0
결과가 조금 이상해 보이는데 인수가 음수일 때 floor는 정수부가 1 감소하며 ceil은 소수부를 버린다. 왜 그런가 하면 음수에서도 버림에 의해 수가 더 작아져야 하고 올림에 의해 수가 더 커져야 하기 때문이다. 그래서 floor, ceil 함수의 동작을 좀 더 일반적으로 표현하면 다음과 같다.
▶ floor : 주어진 인수보다 크지 않은 최대 정수
▶ ceil : 주어진 인수보다 작지 않은 최소 정수
수직선상에서 이 함수들의 동작을 설명해 보면 floor는 인수의 바로 왼쪽 정수값을 구하고 ceil은 바로 오른쪽 정수값을 구한다.
수 체계를 시각화해서 보면 좀 더 쉽게 이해가 갈 것이다. floor는 "마루, 바닥"이라는 뜻이고 ceil은 "천장"이라는 뜻인데 단어뜻과 연관지어 보면 자연스럽게 이해가 될 것이다.
실수 x를 반올림한 값 = floor(x+0.5)
소수점 둘째자리 반올림 값 = floor(x*10+0.5)/10
소수점 둘째자리 반올림 값 = floor(x*10+0.5)/10
5) 절대값 함수
절대값 함수는 인수의 부호를 강제로 양수로 바꾼다. 즉 3은 그냥 3으로 두고 -3은 3으로 바꾸는 것이다. 인수의 타입에 따라 3가지 함수가 준비되어 있다. 이외에 복소수 타입에 대한 절대값 함수도 있으나 여기서는 다루지 않기로 한다.
int abs(int n);
long labs(long n);
double fabs(double x);
위에서부터 순서대로 정수형, long형, 실수형에 대한 절대값을 구한다.
2. 난수 함수
1) 표준 난수 함수
난수(Random Number)란 무작위로 만들어지는 알 수 없는 값이다. 마치 주사위를 던졌을 때 어떤 수가 나올지 미리 알수 없는 것처럼 말이다. 어떤 값을 가지게 될 지 예측할 수 없는 수라는 뜻인데 이런 난수가 필요한 이유는 말 그대로 예측을 허용하지 않기 위해서이다.
만약 포커 게임을 만드는데 게임을 할 때마다 나오는 패가 동일하다면 이 게임은 정말 재미없을 것이다. 또한 슈팅 게임에서 적이 움직이는 경로에 일정한 규칙이 있다거나 퍼즐 게임의 퍼즐이 예측 가능하다면 이 또한 제대로 된 게임이라고 할 수 없다. 패를 무작위로 섞기 위해, 적의 움직임을 미리 알 수 없도록 하기 위해 난수가 필요하다.
난수를 만들 때는 일반적으로 random 이라는 함수를 사용하며 난수 루틴을 초기화할 때는 randomize라는 함수를 사용한다. 그러나 이 함수들은 진짜 함수가 아니라 매크로로 정의되어 있는 가짜 함수들이다. 가짜 함수만 쓸 수 있어도 난수를 만드는데는 큰 불편함이 없지만 내부를 좀 더 정확하게 이해하기 위해 이 매크로 함수들을 분석해 보자. 난수를 만드는 진짜 함수는 다음 두 개이다.
int rand(void);
void srand(unsigned int seed);
rand 함수는 0~RAND_MAX 범위의 수 중에서 무작위로 한 수를 생성해 낸다. RAND_MAX는 컴파일러에 따라 다르지만 일반적으로 32767(0x7ffff)로 정의되어 있다. 그래서 rand 함수를 호출하면 0부터 32767중의 임의의 정수 하나가 리턴된다.
#define randomize() srand((unsigned)time(NULL)) // 완전 난수
randomize 함수는 현재 시간을 사용하여 난수 발생기를 초기화하며 random 함수는 인수로 전달된 n사이의 난수를 발생시킨다. rand, srand 함수보다 훨씬 더 직관적이고 원형이 간단하기 때문에 아주 옛날부터 난수 생성을 위해 이 두 매크로 함수를 사용하는 것이 정석이었다. 그래서 볼랜드사의 터보 C, 볼랜드 C 계열 컴파일러는 이 두 함수를 stdlib.h 헤더 파일에 정의해 놓았다.
그러나 볼랜드 이외의 컴파일러들은 이 매크로를 헤더 파일에 정의해 놓지 않아서 rand, srand 함수를 직접 사용해야 하는 불편함이 있다. 하지만 컴파일러가 제공하지 않는다고 randomize, random 함수를 못 쓰는 것은 아니며 필요하면 이 매크로를 직접 정의해서 사용할 수 있다. 그래서 이 책은 Turboc.h 헤더 파일에 이 두 매크로를 미리 정의해 놓았으며 이 헤더만 포함하면 터보 C를 쓰듯이 두 함수를 자유롭게 사용할 수 있다. 만약 실전에서 이 두 함수가 필요하면 Turboc.h에 있는 매크로 정의문을 복사해서 사용하면 된다.
2) 난수의 생성
random 함수 자체는 간단하지만 응용하기에 따라서는 아주 다양한 유형의 난수를 만들 수 있다. 유형별로 random 함수의 응용예를 보도록 하자.
random(10) // 0~9 까지의 난수
random(89) // 0~88 까지의 난수
random(10)+1 // 1~10까지의 난수
random(20)+10 // 10~29 까지의 난수
random 함수로 생성한 난수에 상수를 더하면 난수의 범위가 평행이동된다.
(3) 난수의 범위가 평행 이동되면 범위의 끝도 같이 이동되므로 미리 계산에 포함하여 범위도 적당히 줄여야 한다. 5~10 사이(10은 제외)의 난수를 만들고 싶다고 해서 random(10)+5라고 호출해서는 안되며 random(5)+5라고 호출해야 한다. 일정한 범위의 난수 생성문을 일반적으로 정의하면 다음과 같다.
▶ a~b사이(b 제외)의 정수 난수를 구할 때 : random(b-a)+a;
▶ a~b까지(b 포함)의 정수 난수를 구할 때 : random(b-a+1)+a;
random(100/2)*2
100/2는 50이므로 random 함수에 의해 0~49사이의 난수가 생성되며 이 값에 2를 곱하면 0~98로 범위가 확장된다. 정수에 2를 곱했으니 생성된 난수는 모두 짝수일 수밖에 없다. 만약에 홀수를 구하고 싶다면 1을 더하면 될 것이다.
random(100)/10.0
random(100)에 의해 0~99까지의 정수가 생성되는데 이 값을 10.0으로 나누면 0.0~9.9까지로 범위가 축소될 것이다. 이때 나누어주는 수는 반드시 실수 상수여야 / 연산자가 실수 나눗셈을 하게 된다. 소수점 두 자리까지 유효한 실수 난수는 0~1000까지 정수 난수를 구한 후 100.0으로 나누면 된다.
(random(5)+5)*(random(2)==0 ? 1:-1)+9
(random(2)==0 ? 1:-1) 연산문은 앞에서 생성한 난수의 부호를 난수로 선택하는 역할을 한다. random(2)가 0이라는 표현은 1/2의 확률을 의미한다. 사실 이 예는 좀 억지스럽고 실용성이 없지만 이런 식으로도 응용할 수 있다는 것을 보여주기에는 충분하다.
int i;
do {
i=random(16);
} while (i!=3 && i!=7 && i!=12 && i!=15);
원하는 난수가 나올 때까지 루프를 계속 돌리기만 하면 된다. 다음 장에서 배울 배열을 사용하면 배열에 원하는 값들을 넣어 놓고 배열의 첨자를 난수로 고를 수도 있다. 이런 식으로 제어구조까지 활용하면 사실 못만들어낼 난수가 없는 셈이다.
난수의 활용 용도는 무궁 무진한데 불규칙한 수의 생성 뿐만 아니라 확률을 제어하고 싶을 때도 사용된다. if (random(n) == 0) { } 조건문은 일정한 확률로 어떤 문장을 실행한다. 예를 들어 if (random(10) == 0) 은 열번에 한 번꼴로, 10%의 확률로 참이 된다. 난수의 범위가 넓을수록 확률은 작아지고 좁을수록 확률이 커진다. 이때 ==0은 별 의미가 없으며 1이나 2와 비교를 해도 똑같은 결과를 얻을 수 있다.
3. 시간 함수
1) time
컴퓨터안에는 시계가 내장되어 있어 항상 정확한 시간을 유지하고 있는데 프로그램에서 시간을 필요로 할 경우 시간 함수로 이 값을 조사할 수 있다. 또한 조사한 시간을 목적에 맞게 조정하거나 변환 및 포맷팅할 수도 있다. 모든 시간 함수의 원형은 time.h 헤더 파일에 선언되어 있으므로 시간 관련 함수를 사용하려면 반드시 time.h를 인클루드해야 한다. 이 책에서 사용하고 있는 Turboc.h가 미리 time.h를 인클루드하고 있으므로 여기서는 그럴 필요가 없지만 실전에서는 그렇지 않음을 명심하자. 시간과 관련된 가장 기본적인 함수는 현재 시간을 구하는 time 함수이다.
time_t time( time_t *timer );
char *ctime( const time_t *timer );
time 함수는 1970년 1월 1일 자정 이후 경과한 초를 조사하는데 리턴 타입인 time_t형은 시스템에 따라 달라지며 윈도우즈에서는 4바이트 정수(typedef long time_t;)로 정의되어 있다. time 함수는 time_t형의 포인터를 인수로 받아 이 인수에 조사된 시간을 채워 주기도 하고 같은 값을 리턴하기도 한다. 둘 중 아무값이나 사용해도 상관없으며 리턴값만 사용할 경우는 인수로 NULL을 전달할 수도 있다. 다음 두 코드는 동일하다.
|
time_t now |
time_t now |
이 함수는 최대 2038년 1월 18일까지의 날짜를 표현할 수 있으며 64비트 버전인 _time64 함수는 3000년 12월 31일까지 표현 가능하다. 이 함수가 조사하는 시간은 초단위이기 때문에 이 값으로부터 우리가 일상적으로 사용하는 시간을 바로 구하기는 무척 어렵다. 또한 세계 표준시인 UTC 포맷으로 되어 있어 우리나라 시간과 일치하지도 않는다.
ctime 함수는 time_t형의 경과초를 출력하기 편리한 문자열 형태로 바꾸며 UTC로 된 시간을 지역 설정에 맞게 조정해 주기도 한다. 지역 설정이란 각 국가의 경도에 따른 세계 표준시와의 차이점과 일광 절약 시간(Daylight Saving time;흔히 Summer Time이라고 한다)의 운영 여부 등에 따라 달라지는데 우리나라의 경우 세계 표준시보다 9시간 더 빠르다.
변환된 문자열은 26문자 길이로 되어 있으며 끝에 개행 문자가 있어 printf 등의 함수로 곧바로 출력할 수 있다.
실행 결과는 다음과 같다. 이 실행 결과를 보면 저자가 일요일 새벽에도 잠을 자지 못하고 원고를 열심히 쓰고 있음을 알 수 있다.
현재 시간은 Sun Sep 05 03:35:27 2004
입니다.
초단위로 된 시간을 문자열 형태로 변환하므로 읽기는 편하지만 영문으로 출력되는데다 개행 코드가 작성되어 있어 다른 문자열 중간에 삽입하려면 개행 코드를 지운 후 사용해야 하는 번거로움이 있다. 다음 두 함수는 날짜와 시간을 문자열 형태로 바로 구하는 좀 더 간단한 함수이다.
char *_strdate(char *datestr);
char *_strtime(char *timestr);
_strdate는 날짜를 MM/DD/YY 포맷으로 구해 datestr 버퍼에 복사하며 _strtime은 시간을 HH:MM:SS 포맷으로 구해 timestr 버퍼에 복사하는데 이 함수가 구해주는 시간은 24시간제이다. 두 함수로 전달되는 버퍼는 널 문자까지 고려하여 최소한 9바이트 이상이어야 한다. ctime이 변환 결과를 저장하기 위해 사용하는 버퍼는 라이브러리에서 미리 할당해 놓은 정적 메모리 영역이며 이 영역은 asctime, gmtime, localtime 등의 함수들이 공유한다. 따라서 상기 함수 중 하나를 호출하면 다른 함수가 작성한 문자열은 파괴되므로 변환한 문자열을 계속 사용하려면 사본을 복사해 두어야 한다.
시간 관련 함수들이 버퍼를 공유하는 이런 설계는 이후 멀티 스레드에서 문제거리가 된다. C 라이브러리 함수를 만들 때는 멀티 스레드라는 것이 없었기 때문에 이런 점을 미처 고려하지 못했다.
2) 시간 구조체
time 함수를 사용하면 현재 시간을 쉽게 구할 수 있고 ctime을 사용하면 이 시간을 문자열로도 바꿀 수 있지만 포맷팅을 마음대로 할 수 없어 무척 불편하다. 시간 포맷을 자유롭게 변경하고 싶다면 경과초 형태로 되어 있는 값에서 각각의 시간 요소를 분리해야 한다. 다음 함수들은 time_t형의 값을 tm 구조체로 변환한다.
struct tm *gmtime(const time_t *timer);
struct tm *localtime(const time_t *timer);
time_t mktime(struct tm *timeptr);
gmtime, localtime 함수는 둘 다 time_t형의 값을 tm 구조체로 변환하는데 gmtime은 세계 표준시로 변환하며 localtime은 지역시간으로 변환한다. 세계 표준시는 잘 사용되지 않으므로 localtime 함수가 훨씬 더 자주 사용된다. 이 두 함수도 라이브러리에 정적으로 할당되어 있는 tm 구조체를 사용하므로 한 함수가 구해 놓은 정보는 다른 함수를 호출하면 파괴된다. mktime 함수는 반대의 변환을 하는데 tm 구조체를 time_t형으로 바꾼다. tm 구조체는 time.h 헤더 파일에 다음과 같이 선언되어 있다.
struct tm {
int tm_sec; /* seconds after the minute - [0,59] */
int tm_min; /* minutes after the hour - [0,59] */
int tm_hour; /* hours since midnight - [0,23] */
int tm_mday; /* day of the month - [1,31] */
int tm_mon; /* months since January - [0,11] */
int tm_year; /* years since 1900 */
int tm_wday; /* days since Sunday - [0,6] */
int tm_yday; /* days since January 1 - [0,365] */
int tm_isdst; /* daylight savings time flag */
};
날짜와 시간을 구성하는 여러 가지 멤버들이 포함되어 있으며 주석도 비교적 상세하게 작성되어 있다. 각 멤버의 이름이 무척 쉽게 작성되어 있어 따로 외울 필요까지는 없지만 멤버마다 베이스가 제각각이므로 쓸 때는 조금 주의해야 한다.
|
멤버 |
설명 |
|
tm_sec |
초(0~59) |
|
tm_min |
분(0~59) |
|
tm_hour |
시간(0~23) |
|
tm_mday |
날짜(1~31) |
|
tm_mon |
월(0~11) |
|
tm_year |
1990년 이후 경과 년수 |
|
tm_wday |
요일(0~6). 0이 일요일 |
|
tm_yday |
년중 날짜(0~365) |
|
tm_isdst |
일광 절약 시간과의 차 |
#include <Turboc.h>
void main()
{
time_t t;
tm *pt;
time(&t);
pt=localtime(&t);
printf("현재 시간 %d년 %d월 %d일 %d시 %d분 %d초입니다.\n",
pt->tm_year+1900,pt->tm_mon+1,pt->tm_mday,
pt->tm_hour,pt->tm_min,pt->tm_sec);;
}
현재 시간 2004년 9월 5일 4시 12분 56초입니다.
시간 요소 사이에 한글을 넣을 수도 있고 시간 요소의 출력 순서를 마음대로 조정할 수 있어서 훨씬 더 자유롭고 깔끔한 출력을 할 수 있다. asctime 함수는 tm 구조체를 문자열로 바꾸는데 ctime 함수와 마찬가지로 출력 결과가 영어로 되어 있어 한글 환경에는 실용성이 없고 개행 문자도 포함되어 있다.
char *asctime(const struct tm *timeptr);
size_t strftime(char *strDest, size_t maxsize, const char *format, const struct tm *timeptr);
strftime 함수는 시간을 다양한 방식으로 포맷팅하는데 첫 번째 인수로 버퍼, 두 번째 인수로 버퍼의 길이, 세 번째 인수로 포맷팅 방식, 네 번째 인수로 tm 구조체를 준다. 세 번째 인수에 포맷팅 서식을 어떻게 지정하는가에 따라 시간을 다양한 형식의 문자열로 바꿀 수 있다.
#include <Turboc.h>
void main()
{
time_t t;
char Format[128];
time(&t);
strftime(Format,128,"%Y %B %d %A %I:%M:%S %p",localtime(&t));
puts(Format);
}
3) 기타 시간 함수
시간은 여러 모로 쓸 데가 많은 정보이다. 다음 함수는 프로그램이 실행을 시작한 후의 경과된 시간(Process Time)을 조사한다.
clock_t clock( void );
clock_t 타입은 long형으로 정의되어 있으며 이 함수가 조사한 값을 CLOCKS_PER_SEC으로 나누면 프로그램 실행 후의 경과 초를 알 수 있다. 이 값은 시스템에 따라 다른데 윈도우즈에서는 1000으로 정의되어 있다.
typedef long clock_t;
#define CLOCKS_PER_SEC 1000
실행 후의 경과 시간 자체는 별로 쓸 데가 없지만 두 작업 시점간의 시간을 계산하거나 일정한 시간만큼 특정 작업을 계속하고 싶을 때 clock 함수가 조사하는 시간이 기준점으로 사용될 수 있다.
delay도 정확한 시간을 지연시키기는 하지만 기다리는동안 다른 일을 할 수 없다는 점이 다르다. 시스템 속도에 상관없이 일정 시간동안 어떤 작업을 하고 싶다면 clock 함수로 구한 시간을 이용하면 된다. 다음 함수는 두 시간값의 차를 구해준다.double difftime(time_t timer1, time_t timer0);
실수형을 리턴하는 것으로 되어 있지만 계산 결과가 초단위로 되어 있기 때문에 정밀한 시간 계산이나 코드의 성능 측정 등에 쓰기에는 무리가 있다.
OSI (Open Systems Interconnection) ; 개방형 시스템간 상호 접속
|
Open Systems Interconnection 참조 모델 (그림) OSI는 네트웍 내에서 양측의 사용자가 통신하기 위한 표준 참조 모델이다. 이 모델은 제품 개발이나, 네트웍을 이해하는데 사용된다. 이 그림은 빈번히 사용되는 인터넷 제품들 및 서비스들이 모델 내에서 어느 계층에 해당하는가를 보여주고 있다.
OSI는 7 계층으로 통신을 나누는데, 이 계층들은 다시 2개의 그룹으로 나뉜다. 상위 4 계층은 이용자가 메시지를 주고받는데 사용된다. 네트웍 계층까지의 아래의 3 계층은 메시지가 호스트를 통과 할 수 있도록 한다. 컴퓨터에 보내진 데이터는 위 계층으로 전달된다. 다른 컴퓨터에 보내진 메시지는 위 계층으로 전달되지 않고 다른 호스트로 전달된다.
7 계층을 하나하나 살펴보면 다음과 같다.
OSI 참조모델은 네트웍 내에서 메시지가 한쪽에서 다른 쪽으로 보내졌을 때, 각 단에서 필요한 관련 기능들의 7개 계층으로 설명된다. 기존의 네트웍 제품이나 프로그램들은, 이 계층적 구조 내에 그것이 어울리는 곳에서 부분적으로 설명될 수 있다. 예를 들어, TCP/IP는 대체로 인터넷상에서 통신을 지원하는 일련의 제품들로서 다른 인터넷 프로그램들과 함께 일괄적으로 포함된다. 이러한 일련의 제품들로는 FTP, Telnet, HTTP, 전자우편 및 기타의 것들로 구성된다. 비록 TCP는 OSI의 전송계층에, IP는 네트웍 계층에 잘 들어맞는다 할지라도, 기타 다른 프로그램들은 세션이나, 표현 및 응용계층에 약간 부정확하게 맞는다.
이 그림에는 네트웍 계층 보다 상위에 있는 계층 내의 인터넷 관련 프로그램들만을 포함하였다. OSI는 다른 네트웍 환경에서 적용될 수 있다. 응용 및 표현계층 아래에 많은 사각형들은 표시된바와는 달리 이러한 계층에 깔끔하게 들어맞지는 않는다. 그러나, OSI 참조모델을 완벽하게 따르는 일련의 통신 제품들은 각 계층에 정확히 들어 맞을 수 있다. OSI[오에스아이]는 통신 네트웍으로 구성된 컴퓨터가 어떻게 데이터를 전송할 것인가에 대한 표준규약 또는 참조 모델이다. 이것의 목적은 통신 제품을 만들 때 다른 제품과 모순됨이 없이 통신하도록 유도하는 것이다. 이 참조 모델은 통신의 종단에서 이루어지는 기능을 7 계층으로 정의했다. OSI가 잘 정의된 계층마다 관련된 기능을 따르도록 강하게 고수하지 않아도, 대부분의 제품들은 OSI 모델에 관련된 정의들을 따르기 위해 노력한다. OSI 모델은 또한 모든 사람이 동일한 관점에서 통신에 대해 교육하고, 논의하는 유일한 참조 모델로서 중요한 가치가 있다. 주요 컴퓨터와 통신 회사 대표자들에 의해 1983년부터 개발이 시작된 OSI는 본래 인터페이스 사이의 상세 규정을 시도했다. 그러나 위원회는 다른 것들 간에 상세 인터페이스 규정을 개발할 수 있는 공통의 참조 모델을 확립하기로 결정하였으며, 그것은 표준이 될 수 있었다. OSI는 ISO에 의해서 국제 표준으로 채택되었다. 현재, 이것은 ITU의 권고 X.200 이다. OSI의 주된 개념은 통신 네트웍으로 구성된 두개의 종단 이용자 사이에서, 통신 처리를 각 계층이 가지고 있는 특별한 기능을 가지고 계층별로 나눌 수 있도록 하는 것이다. 각 통신 이용자는 7 계층의 기능을 갖는 컴퓨터를 이용한다. 이용자들 사이에 메시지가 주어지면, 컴퓨터에서 한 계층씩 아래로 각 층을 통과하여 데이터가 흐르게되고, 다른 쪽에서는 메시지가 도착할 때 메시지를 받는 컴퓨터는 한 계층씩 위로 통과하여 이용자에게 전달 될 것이다. 실제로 이러한 7 계층의 기능을 제공하는 프로그램이나 장치는 컴퓨터 운영체계, 웹 브라우저와 같은 응용프로그램, TCP/IP 또는 다른 트랜스포트 네트웍 프로토콜과 이용자의 컴퓨터에 구성된 회선을 사용할 수 있는 소프트웨어 및 하드웨어가 함께 결합된다. |
|

'old > 용어정리' 카테고리의 다른 글
| big-endian and little-endian (0) | 2011.02.17 |
|---|---|
| layer and layering ; 계층, 계층화 (0) | 2010.11.18 |
| Jolt (0) | 2010.11.18 |
| IT (information technology) ; 정보기술 (0) | 2010.11.18 |
| ISV (independent software vendor) (0) | 2010.11.18 |
layer and layering ; 계층, 계층화
|
컴퓨터 프로그래밍에서, 계층화는 개별 단계들 속으로 순차대로 수행되고 종료되는 프로그래밍 조직으로서, 각 단계의 결과를 어느 정도 분량의 정보를 송신하거나 수신하는 것과 같이 전체적인 기능에 이르기까지, 다음 프로그램이나 계층에 전달하기 위한 특정 인터페이스에 의해 정의된다. 통신 프로그램들도 종종 계층화 된다. 통신 프로그램의 참조 모델인 OSI는 통신의 양단에 하나씩 있는 두 프로그램들 내의 계층화된 프로토콜 모음으로서, 각 계층별로 동일한 셋을 사용한다. OSI는 7 계층으로 구성되며, 각각은 컴퓨터들 사이에서 프로그램과 프로그램 사이의 통신을 위해 수행되어야할 여러 가지 기능을 반영한다. TCP/IP는 인터넷 통신을 위해 전송과 네트웍 주소 기능을 제공하기 위해 TCP와 IP라는 두 개의 계층을 가지고 있는 프로그램의 예이다. TCP/IP와 그외 다른 계층화 프로그램들을, 때로 프로토콜 스택이라고 부르기도 한다. |
'old > 용어정리' 카테고리의 다른 글
| big-endian and little-endian (0) | 2011.02.17 |
|---|---|
| OSI (Open Systems Interconnection) ; 개방형 시스템간 상호 접속 (0) | 2010.11.18 |
| Jolt (0) | 2010.11.18 |
| IT (information technology) ; 정보기술 (0) | 2010.11.18 |
| ISV (independent software vendor) (0) | 2010.11.18 |
Jolt
|
Jolt는 두 컵의 커피 상당량이 들어있는 미국의 청량음료로서, 프로그래머, 대학생, 인터넷 서퍼, 그리고 늦은 밤이나 새벽시간까지 깨어있어야 하는 사람들이 주로 찾는다. 누군가는 Jolt를 "인터넷을 움직이게 하는 연료"라고 표현하기도 한다. Jolt 한 깡통이나 한 병은 펩시콜라나 코카콜라가 가지고 있는 코카인 량의 두 배 가량을 포함하고 있다. Jolt 신봉자들은 고유의 웹페이지를 만들었는데, 호주와 스웨덴에 있는 몇 개와 독일어로 된 Jolt 페이지를 포함하여, 야후에만도 9개나 올라있다. 공식적인 Jolt 팬클럽 페이지와 몇몇 다른 페이지들에서는, Jolt의 카페인 량을 다른 청량음료와 비교한 그림 자료를 제공하고 있다. 가장 재미있는 Jolt 웹페이지는 Jolt Cola 홈페이지이다. |
'old > 용어정리' 카테고리의 다른 글
| OSI (Open Systems Interconnection) ; 개방형 시스템간 상호 접속 (0) | 2010.11.18 |
|---|---|
| layer and layering ; 계층, 계층화 (0) | 2010.11.18 |
| IT (information technology) ; 정보기술 (0) | 2010.11.18 |
| ISV (independent software vendor) (0) | 2010.11.18 |
| IS (information system[s] or information services) ; 정보시스템 또는 정보서비스 (0) | 2010.11.18 |
IT (information technology) ; 정보기술
IT[아이티]라는 용어는, 다양한 형태(업무용 데이터, 음성대화, 사진, 동영상, 멀티미디어 프레젠테이션, 및 심지어 아직 나타나지 않은 형태의 매체를 모두 포함)로 정보를 만들고, 저장하고, 교환하고, 사용하는 데 필요한 모든 형태의 기술을 아우른다. 이것은 정보통신이나 컴퓨터 기술 모두를 하나의 낱말로 나타낼 수 있는 편리한 용어이다. "정보혁명"을 주도하는 것이 바로 정보기술이다.
'old > 용어정리' 카테고리의 다른 글
| layer and layering ; 계층, 계층화 (0) | 2010.11.18 |
|---|---|
| Jolt (0) | 2010.11.18 |
| ISV (independent software vendor) (0) | 2010.11.18 |
| IS (information system[s] or information services) ; 정보시스템 또는 정보서비스 (0) | 2010.11.18 |
| interoperability ; 상호 운용성 (0) | 2010.11.18 |
ISV (independent software vendor)
|
ISV는 하나 이상의 컴퓨터 하드웨어나 운영체계 플랫폼에서 실행되는 소프트웨어 제품을 만들고 판매하는 회사를 말한다. 마이크로소프트, IBM, 휴렛패커드, 애플 등과 같이 플랫폼을 만드는 회사들은, "비즈니스 파트너"라고 불리는 특별한 계획에 의거하여 ISV를 격려하고, 지원을 제공한다. 일반적으로, 하나의 플랫폼에서 더 많은 응용프로그램들이 실행되면, 고객들에게 더 많은 가치를 제공하게 된다. 물론, 마이크로소프트, IBM 등과 같은 플랫폼 제작회사들도 역시 응용프로그램들을 만들지만, 모든 것을 자체적으로 만들기에는, 요구되는 자원이나 특별한 지식들을 가지고 있지 못한 경우가 대부분이다. 윈도우95나 매킨토시 플랫폼에서 실행되는 모든 프로그램들을 생각해보면, 거기에 얼마나 많은 ISV들이 있는지를 알게 될 것이다. 일부 ISV들은 IBM의 소규모 비즈니스용 AS/400 등과 같이 특정 운영체계에 초점을 맞추며, 거기에는 수천 개 이상의 ISV 응용프로그램들이 있다. 다른 ISV들은 공학 등과 같은 특정 응용분야에 특화되어 있으며, 주로 최상위 유닉스 기반의 워크스테이션 플랫폼에 사용되는 소프트웨어를 개발한다. ISV는 플랫폼에 추가되는 소프트웨어를 만들고 판매한다. OEM 회사들은 대형 제품을 만들기 위하여 하드웨어 플랫폼 구성요소들을 사용한다. VAR들은 자신들의 소프트웨어 제품 패키지에 플랫폼 소프트웨어를 통합시킨다. |
'old > 용어정리' 카테고리의 다른 글
| Jolt (0) | 2010.11.18 |
|---|---|
| IT (information technology) ; 정보기술 (0) | 2010.11.18 |
| IS (information system[s] or information services) ; 정보시스템 또는 정보서비스 (0) | 2010.11.18 |
| interoperability ; 상호 운용성 (0) | 2010.11.18 |
| instruction ; 명령어 (0) | 2010.11.16 |
IS (information system[s] or information services) ; 정보시스템 또는 정보서비스
'old > 용어정리' 카테고리의 다른 글
| IT (information technology) ; 정보기술 (0) | 2010.11.18 |
|---|---|
| ISV (independent software vendor) (0) | 2010.11.18 |
| interoperability ; 상호 운용성 (0) | 2010.11.18 |
| instruction ; 명령어 (0) | 2010.11.16 |
| internationalization ("I18N") ; 국제화 (0) | 2010.11.16 |
interoperability ; 상호 운용성
|
상호 운용성은 시스템 또는 제품이, 고객 측의 특별한 노력 없이도 다른 시스템이나 제품과 함께 잘 동작하기 위한 능력이다. 상호 운용성은 "네트웍이 곧 컴퓨터이다"라는 개념이 현실화되어가면서, 정보기술 제품의 품질에 있어 그 중요도가 점차 커지고 있다. 이러한 이유 때문에, 이 용어가 제품 설명서 내에 광범위하게 사용되고 있다. 제품들은 다음 중 하나, 또는 둘 모두를 사용하여 다른 제품들과의 상호 운용성을 이룬다
첫 번째 접근방식의 좋은 예가, 월드와이드웹을 위해 개발되었던 일련의 표준들이다. 이러한 표준들에는 TCP/IP, HTTP, 그리고 HTML을 포함한다. 두 번째 종류의 상호 운용성 접근방식은 CORBA와 ORB에 의해 예증되었다. "호환성"이라는 단어도 상호 운용성과 관련이 있는 용어다. 표준과 양립할 수 있는 제품이라도, 동일한 표준에 부합되는 다른 제품들과 공동이용이 가능하다 (또는 브로커를 통하여 상호 운용성을 달성한다). |
'old > 용어정리' 카테고리의 다른 글
| ISV (independent software vendor) (0) | 2010.11.18 |
|---|---|
| IS (information system[s] or information services) ; 정보시스템 또는 정보서비스 (0) | 2010.11.18 |
| instruction ; 명령어 (0) | 2010.11.16 |
| internationalization ("I18N") ; 국제화 (0) | 2010.11.16 |
| I/O (input/output) ; 입출력 (0) | 2010.11.16 |
1. 지역 변수
1) 전역 변수와 지역 변수
기억 부류(Storage Class)란 변수가 저장되는 위치에 따라 결정되는 변수의 여러 가지 성질을 의미한다. 변수가 어디에 생성되는가에 따라 통용 범위와 파괴 시기 등의 특징이 결정된다. 이 내용은 C의 문법 체계를 이해하는데 상당히 중요한 비중을 차지하므로 숙독하여 완전히 이해하도록 하자. 기억 부류에는 4가지 종류가 있는데 일단 도표로 특성을 요약하였다.
|
기억 부류 |
전역 |
지역 |
정적 |
레지스터 |
|
지정자 |
extern |
auto |
static |
register |
|
저장 장소 |
정적 데이터 영역 |
스택 |
정적 데이터 영역 |
CPU의 레지스터 |
|
선언 위치 |
함수의 외부 |
함수의 내부 |
함수의 내부 |
함수의 내부 |
|
통용 범위 |
프로그램 전체 |
함수의 내부 |
함수의 내부 |
함수의 내부 |
|
파괴 시기 |
프로그램 종료시 |
함수 종료시 |
프로그램 종료시 |
함수 종료시 |
|
초기값 |
0으로 초기화 |
초기화되지 않음 |
0으로 초기화 |
초기화되지 않음 |
#include <Turboc.h>
void func();
int global; // 함수 외부에서 선언되었으므로 전역변수
void main()
{
int local; // main 함수의 지역변수
global=1; // 가능
local=2; // 가능
i=3; // 불가능
}
void func()
{
int i; // func 함수의 지역변수
global=1; // 가능
local=2; // 불가능
i=3; // 가능
}
(1) 변수의 선언 위치가 다르다. 두 부류의 가장 뚜렷한 차이점인데 전역변수는 함수 바깥에서 선언하고 지역변수는 함수 내부에서 선언한다. 위 예제에서 global 변수는 main 함수 이전에 선언되었으므로 전역변수이고 local과 i는 각각 main 함수와 func 함수 내부에서 선언되었으므로 지역변수이다.
단, 아무리 전역변수라 하더라도 자신이 선언된 이후에만 사용할 수 있다. 만약 위 예제에서 global 변수를 main 다음에 선언한다면 main에서는 global을 참조할 수 없다. 물론 func에서는 참조할 수 있다. C 컴파일러는 1패스 방식으로 동작하기 때문에 변수든 함수든 사용하기 전에 항상 선언을 먼저 해야 한다.
반면 지역변수는 자신이 선언된 함수에 소속되어 있기 때문에 함수 외부에서는 이 변수를 사용할 수 없다. 변수의 값을 읽지도, 쓰지도 못하며 변수의 존재 자체가 알려지지 않기 때문에 이 변수를 들먹거리는 것조차 허용되지 않는다. 지역변수는 함수가 자신의 임무를 수행하기 위해 잠시 쓰고 버리는 것이다.
main에서 자신의 지역변수 local에 값을 대입하거나 func 함수에서 자신의 지역변수 i를 사용하는 것은 가능하다. 그러나 main에서 i 를 참조하거나 func에서 local을 참조하는 것은 불가능하다. main 함수에게 i라는 변수는 없는 것과 마찬가지이다.
전역변수는 프로그램에 소속되어 있고 모든 함수에서 사용 가능해야 하므로 프로그램이 실행중인 동안에는 파괴되지 않는다. 실행 직후에 생성되어 프로그램이 실행되는 동안에는 계속 메모리를 차지하고 있으며 프로그램이 종료되면 비로소 파괴된다. 즉, 전역변수는 프로그램과 운명을 같이 한다.
지역변수는 특정 함수 내부에서만 사용되므로 함수가 실행중일 때만 메모리를 차지하며 함수가 끝나면 변수의 생명도 끝이 난다. 함수의 임무를 위해 생성되는 임시 기억 장소이기 때문에 함수가 종료되면 더 이상 이 변수를 유지할 필요가 없어진다. 즉, 지역변수는 자신이 속해 있는 함수와 운명을 같이 한다. 함수가 호출되면 생성되고 함수가 끝나면 파괴된다. 그러다가 또 함수가 호출되면 생성되고 파괴되기를 계속 반복한다.
위 예제에서 global은 프로그램 종료시에 파괴되며 local은 main 함수 종료시에, i는 func 함수 종료시에 파괴된다. main의 지역변수는 우연히 전역변수와 생성, 파괴 시기가 거의 동일한데 이는 main 함수 자체가 프로그램 그 자체이기 때문이다.
프로그램은 실행에 필요한 임시적인 정보들을 스택에 차곡차곡 저장한다. 지역변수, 인수, 함수 실행후 돌아갈 번지 등이 스택에 생성되었다가 사라졌다가를 반복한다. 지역변수는 임시 저장소인 스택에 생성되기 때문에 통용 범위가 함수로 국한되고 함수가 종료되면 같이 사라지는 것이다.
반면 지역변수는 별도의 초기식이 없을 경우 초기화되지 않는다. 따라서 무슨 값을 가지게 될 지 알 수 없는데 이때 초기화되지 않은 값을 쓰레기값(garbage)이라고 한다. 물론 선언할 때 초기값을 명시적으로 지정하면 초기화할 수도 있다. 초기값이 없을 때 지역변수를 초기화하지 않는 이유는 전역변수와는 달리 함수가 호출될 때마다 변수가 새로 생성되기 때문이다. 매번 변수를 초기화하자면 그만큼 실행 속도가 느려지므로 초기화를 하지 않는다.
지역변수는 함수 내부에서만 사용되므로 설사 지역변수의 쓰레기값이 문제가 된다 하더라도 그 함수만 점검하면 되지만 전역변수가 쓰레기값을 가지게 되면 프로그램 전체에 걸쳐 말썽을 부릴 수도 있다. 그래서 전역변수에 대해서는 초기값을 주지 않아도 쓰레기를 치우지만 지역변수는 그렇게 하지 않는다. 만약 지역변수에 쓰레기값이 들어가는 것이 싫다면 명시적으로 초기화를 해야 한다.
2) 지역 변수의 장점
지역변수는 함수 내부에서만 사용할 수 있고 함수가 끝나면 파괴되는데 비해 전역변수는 모든 함수에서 자유롭게 사용할 수 있고 프로그램이 실행중인 동안은 계속 유지된다. 통용 범위도 넓고 지속 기간도 길기 때문에 모든 면에서 지역변수보다는 사용하기 편리하며 지역변수로 할 수 있는 거의 대부분의 일은 전역변수로도 할 수 있다.
그렇다면 지역변수라는 것은 아예 사용하지 말고 모든 변수를 전역으로 사용하면 될 것이다. 지역변수를 쓰지 않고도 얼마든지 프로그램을 작성할 수 있으며 실제로 지역변수를 지원하지 않는 언어도 있다. 어셈블리에서는 사실 변수라는 개념 자체가 없고 모든 것이 메모리 주소이기 때문에 모든 값은 전역이다(스택에 의도적으로 임시 변수를 생성할 수는 있다). 고전적인 베이직 언어에서도 지역변수라는 것이 없다. 하지만 C나 파스칼, 자바, 비주얼 베이직 같은 근대적인 언어들은 모두 지역변수의 개념을 지원한다.
심지어는 PHP나 ASP, 자바 스크립트 같은 스크립트 언어들까지도 지역변수를 지원한다. 왜 이런 언어들이 지역변수를 지원하는가 하면 프로그램의 구조화에 큰 도움을 주고 유지, 보수를 쉽게 해주는 등의 여러 가지 장점이 있기 때문이다.
장점
지역변수는 함수가 자신이 필요로 하는 모든 정보를 다 가질 수 있도록(Self Contained) 해 줌으로써 함수의 독립성을 높여 준다. 그렇다면 이런 식으로 함수를 완전히 독립적으로 작성한다면 함수끼리의 정보 교환은 어떻게 하는가? 부품은 혼자 동작하는 게 아니므로 부품간의 정보 교환은 반드시 필요할 것인데 이럴 경우라도 전역변수는 사용할 필요가 없다. 왜냐하면 이럴 때 쓰라고 만들어 놓은 인수와 리턴값이라는 좋은 장치가 있기 때문이다. 함수끼리 정보를 주고 받기 위해서는 인수와 리턴값을 사용하는 것이 정석이다.
그러나 지역변수는 디버깅하기 아주 쉽다. 일단 지역변수를 많이 쓰면 전역변수의 수가 상대적으로 줄어들게 되므로 관찰 대상 변수의 범위가 대폭 좁아진다. 또한 지역변수는 말썽을 부려봐야 자신이 소속된 함수안에서만 유효하므로 그야말로 뛰어봤자 벼룩이고 부처님 손바닥안의 손오공이다. 특정 지역변수가 말썽을 부린다면 그 함수 내부만 정밀하게 점검해 보면 금방 문제점을 발견할 수 있다.
프로그램이 대략 1000줄 정도만 되도 프로그램 개발 속도를 좌지우지하는 중요한 관건은 디버깅 속도이다. 프로그램 개발 기간에 소요되는 시간 중의 70%가 에러를 잡아내는 디버깅이라고 하지 않는가? 대형 프로젝트나 팀 프로젝트에서는 디버깅을 얼마나 빨리 할 수 있는가가 프로젝트의 성공을 결정한다. 디버깅의 간편함이 가지는 의미는 상상외로 크다.
지역변수가 전역변수에 비해 월등히 많은 장점을 가지고 있다. 전역변수는 편리하기는 하지만 복잡한 문제를 일으킬 수 있기 때문에 전역변수의 사용은 가급적이면 자재하는 것이 좋다. 전역변수를 전혀 사용하지 않고도 프로그램을 작성할 수 있다는 것이 이미 수학적으로 증명되어 있으며 전역변수를 병적으로 싫어하는 개발자들도 있다.
3) 외부 변수
[지정자] 타입 변수명;
지정자(Specifier)는 기억 부류를 비롯하여 상수 지정, 최적화 금지 등 변수의 여러 가지 성질을 지정하는 키워드인데 필요없을 경우 생략할 수도 있다. 기억 부류를 지정할 때는 auto, extern, static, register 등의 키워드를 사용하는데 먼저 지역변수를 지정하는 auto 키워드에 대해 알아보자.
auto int i, sum;
변수를 지역변수로 선언할 때는 변수의 타입앞에 auto 키워드를 붙인다. 일반적으로 티폴트값이 auto이기 때문에 우리는 생략해서 사용한다.
- 함수 내부에서 사용되면 지역변수가 된다.
- 함수 외부에서 사용되면 전역변수가 된다.
extern int value;
extern 키워드는 변수가 외부 어딘가에 선언되어 있다는 것을 알리는 역할을 한다.
외부에 선언되어 있는 경우에도 사용하지만 뒷쪽에 선언되어 있는 변수를 사용할 때에도 쓰인다.
2. 정적 변수
1) 정적 변수
정적변수(Static Variable)는 전역변수와 지역변수의 성격을 동시에 가지는 좀 특별한 기억 부류이다. 앞의 도표에 기록되어 있는 정적변수의 특징들을 살펴보자.
■ 선언 위치는 지역변수와 마찬가지로 함수의 선두이다.
■ 통용 범위는 지역변수와 마찬가지로 함수 내부로 국한된다.
■ 저장 장소는 전역변수가 저장되는 정적 데이터 영역이다.
■ 정적 데이터 영역에 저장되므로 프로그램 실행중에 항상 존재한다.
■ 초기값 지정이 없으면 0으로 초기화되고 프로그램 실행시 단 한 번만 초기화된다.
정적변수의 성질을 요약하자면 저장 장소는 전역변수이되 통용 범위는 지역변수라 할 수 있다. 정적변수를 선언할 때는 반드시 static이라는 지정자를 붙여야 한다.
static int i;
static double d;
이렇게 선언하면 i나 d는 정적변수가 되어 정적 데이터 영역에 저장되며 통용 범위는 선언문이 있는 함수 내부로 국한된다.
정적변수에서 한가지 유의할 점은 이 변수가 언제 초기화되는가 하는 점이다. 함수 선두에서 정적변수를 선언하고 있으므로 함수가 호출될 때마다 초기화될 것 같지만 그렇지 않으며 함수가 최초로 호출될 때 단 한 번만 초기화된다. 사실 초기화라는 말 자체에 이미 일회성의 의미가 내포되어 있지 않은가? 초기화되는 코드가 호출될 때마다 실행된다면 이 변수가 값을 계속 유지하지 못할 것이다.
또 만약 정적변수 선언문에서 초기화를 하지 않으면 전역변수와 마찬가지로 0으로 자동 초기화된다. 함수 내부에서 큰 배열을 선언하고 초기화할 때는 초기화 시간을 절약하기 위해 정적으로 선언하여 한 번만 초기화하도록 해야 한다. 그렇지 않으면 함수가 호출될 때마다 큰 배열이 매번 생성, 초기화, 파괴를 반복하므로 느려진다.
함수 내부에서 선언된 정적변수를 내부 정적변수라고 한다. 정적변수는 그 특성상 특정 함수 전용으로 선언하는 경우가 많기 때문에 보통 정적변수라고 하면 내부 정적변수를 의미한다. 흔하지는 않지만 함수 외부에서도 정적변수를 선언할 수 있는데 이렇게 선언된 변수를 외부 정적변수라고 한다. 외부 정적변수는 특정 함수에 소속되어 있지 않으므로 일반적으로 전역변수와 같은 성질을 가진다.
다만 전역변수와 다른 점은 extern 선언에 의해 외부 모듈로 알려지지 않는다는 점이다. 즉 자신이 선언된 모듈에서만 사용할 수 있는 모듈 전역변수가 된다. 외부에서 extern 선언을 하더라도 이 변수를 참조할 수 없게 된다.
전역변수이면서도 외부에 알려서는 안되는 그런 변수가 필요할 때 외부 정적변수를 사용한다. 주로 모듈의 재활용성을 높이기 위해 사용하는데 구체적인 예를 들어 보자. 그래픽 관련 함수들을 제공하는 graphic.cpp와 graphic.h를 아주 공들여서 제작했는데 이 모듈에서 mode, color 같은 전역변수를 사용하고 있다고 하자. 이 모듈을 쓰고 싶은 사람이 graphic.* 파일만 복사해서 사용하면 되도록 하고 싶다.
그런데 이 모듈을 사용하는 프로젝트에 이미 mode, color라는 전역변수가 사용되고 있다면 명칭의 충돌이 발생하게 될 것이고 양쪽 중 하나는 변수의 이름을 바꾸어야 한다. 이럴 때 mode, color 변수를 외부 정적변수로 선언하면 다른 모듈에는 알려지지 않으므로 이름의 충돌을 방지할 수 있게 되고 이 모듈은 아무 프로젝트에서나 재활용하기 쉬워진다.
2) 레지스터 변수
레지스터형 변수는 앞에서 논한 세 개의 기억 부류와 좀 다른 유별난 점이 있다. 지역, 전역, 정적변수들은 정적 데이터 영역이든 스택이든 어쨌든 메모리의 한 구석에 생성되지만 레지스터형 변수는 메모리가 아닌 CPU의 레지스터에 저장된다. 레지스터(Register)란 CPU를 구성하는 부품 중 하나이며 CPU가 데이터를 처리하기 위해 사용하는 임시 작업장이라고 생각하면 된다.
컴퓨터의 가장 핵심 부품인 CPU의 한 가운데에 있는 기억 장소이기 때문에 레지스터의 속도는 메모리와 비교가 되지 않을 정도로 빠르다. 값을 읽거나 쓰는데 수십억분의 1초 정도밖에 걸리지 않는다. CPU의 종류에 따라 다르지만 레지스터는 보통 10개~20개 정도밖에 없는 아주 귀한 기억 장소인데 여기에 변수를 저장하면 이 변수를 참조하는 문장의 속도가 빨라진다.
레지스터의 크기는 CPU의 비트수를 결정하는 중요한 기준인데 레지스터가 32비트면 32비트 CPU라고 부른다. 386이후부터 최신의 팬티엄 4까지 현재까지 우리가 사용하는 CPU는 대부분 32비트이므로 레지스터들도 전부 32비트이고 따라서 레지스터에 저장할 수 있는 변수의 타입은 int, unsigned, 포인터 형 등의 32비트형뿐이다. double같은 실수형은 저장할 수 없으며 구조체나 배열 따위는 당연히 안된다. 에러는 아니지만 지정해 봐야 무시당한다.
CPU의 레지스터 개수가 많지 않기 때문에 레지스터형 변수는 두 개까지만 선언할 수 있다. 컴파일러나 플랫폼에 따라 레지스터형 변수를 위해 할당하는 레지스터가 다른데 인텔 플랫폼에서는 많이 사용되지 않는 ESI, EDI 레지스터를 사용한다. 만약 세 개 이상의 레지스터형 변수를 선언하면 최초 두 개까지만 레지스터형이 되고 나머지는 지역변수가 된다.
register int r; // 레지스터형 변수 r선언
register double d; // 실수는 레지스터형 변수가 될 수 없음. 지역변수로 선언된다.
register a,b,c; // a,b만 레지스터형 변수가 되고 c는 지역변수가 된다.
레지스터는 한정된 자원이기 때문에 일시적으로 사용할 지역변수에만 지정할 수 있으며 전역변수에는 레지스터 기억 부류를 지정할 수 없다. 프로그램과 생명을 같이 하는 전역변수가 레지스터 하나를 차지한다면 프로그램 실행중인 동안 레지스터 하나가 묶여 버리게 될 것이다. 전역변수에 register 기억 부류를 지정하면 명백한 에러로 처리된다. 지역변수 또는 함수의 형식 인수에 대해서만 이 기억 부류를 사용할 수 있다.
레지스터형 변수를 사용하는 이유는 조금이라도 더 빠른 속도를 얻기 위해서이다. 대규모의 루프를 돌린다거나 할 때 루프 제어 변수를 레지스터형으로 선언하면 이 변수의 읽기, 증감 속도가 빨라지므로 전체 루프의 실행 속도가 빨라질 것이다.
레지스터형 변수는 메모리에 생성되는 것이 아니므로 &연산자는 사용할 수 없다. 레지스터는 CPU 내부에 있기 때문에 번지를 가지지 않으므로 &연산자로 이 변수의 메모리 주소를 조사할 수 없다. 그러나 레지스터형 포인터 변수가 번지를 기억할 수는 있으므로 *연산자를 사용하는 것은 가능하다. C 스팩에는 레지스터형 변수와 &, * 연산자의 관계가 이렇게 규정되어 있으며 상식적으로 이해가 갈 것이다.
3) 정적 함수
기억 부류 중에 함수에 적용되는 것은 정적(static) 기억 부류밖에 없다. 정적 함수는 특정 모듈에서만 사용할 수 있는데 앞에서 살펴본 외부 정적변수의 특성과 유사하다. 함수 정의문 앞에 static이라는 지정자만 붙이면 이 함수는 정적 함수가 된다.
static void func()
{
....
}
정적 함수와 반대되는 개념에 대해 별다른 명칭은 없고 굳이 이름을 붙인다면 비정적 함수나 외부 함수 정도가 될 것이다. 외부 함수는 별다른 지정이 없는 한 외부로 항상 알려지며 원형 선언만 하면 어떤 모듈에서나 이 함수를 호출할 수 있다.
그러나 정적 함수는 특정 모듈에서만 사용하도록 정의된 것이므로 외부에서 원형을 선언한다 하더라도 이 함수를 호출할 수 없다. 외부에서 그 존재를 알 수 없도록 해야 하는 이유는 외부 정적변수의 경우와 마찬가지로 이름 충돌을 방지하기 위해서이다. 재사용을 위해 작성한 모듈에서 ReadFile이라는 함수를 사용하는데 이 이름이 너무 일반적이어서 프로젝트내의 다른 함수명과 충돌될 것 같으면 이 함수를 static으로 선언하면 된다.
3. 통용 범위
1) 통용 범위 규칙
변수나 함수, 태그 같은 명칭은 상호 구분되어야 하므로 중복되어서는 안된다. 그래서 같은 이름을 가진 두 개의 변수를 선언할 수 없다. 다음과 같이 작성하면 에러로 처리된다.
void main()
{
int i;
double i;
i라는 명칭으로 정수형 변수와 실수형 변수를 동시에 선언했다. 이유를 설명할 필요도 없이 이 코드는 에러로 처리된다.
'i' : redefinition; different basic types
i라는 명칭이 정수형으로 선언되었다가 실수형이라는 다른 타입으로 중복 선언되었다는 뜻이다. 이름이 중복되면 다음에 i를 참조할 때 정수형 변수 i를 의미하는 것인지 실수형 변수 i를 의미하는 것인지 구분할 수 없는 모호함이 발생할 것이다. 컴퓨터 프로그램의 논리에 모호함이란 절대 있을 수 없으므로 명칭의 중복은 허락되지 않는다.
명칭이 중복되지 말아야 한다는 것은 지극히 상식적이다. 그러나 이 법칙에 예외가 있는데 통용 범위가 다른 명칭끼리는 같은 이름을 가질 수도 있다. 다음 예를 보자.
void func()
{
int i;
....
void proc()
{
double i;
....
func 함수에서는 i를 정수형으로 선언했고 proc 함수에서는 같은 이름의 i를 실수형으로 선었했지만 논리적으로 아무 문제가 없다. 둘 다 지역변수이고 통용 범위가 분명히 다르기 때문에 같은 명칭 i를 참조하더라도 func 함수에서는 정수형으로, proc 함수에서는 실수형으로 구분할 수 있어 모호함이 발생하지 않는다.
2) 블록 범위
앞에서 지역변수란 함수 내부에서 선언된 변수라고 했는데 이는 어디까지나 편의상 이해하기 쉽도록 설명한 것이다. 이제 통용 범위까지 살펴 봤으므로 지역변수를 좀 더 정확하게 정의해 보도록 하자. 지역변수는 { } 괄호안의 블록에 선언된 변수를 의미하며 변수가 선언된 블록 내부에서만 통용된다. { } 괄호안에서만 통용되는 범위를 블록 범위라고 하는데 { } 괄호가 보통 함수의 시작과 끝을 나타내고 함수 선두에 지역변수를 선언하는 경우가 많기 때문에 지역변수의 통용 범위는 함수 내부가 되는 것이다.
지역변수의 통용 범위는 정확하게 함수 내부가 아니고 선언된 블록의 내부이다. 그래서 함수 내부안에 { } 블록을 만들고 이 안에 또 다른 지역변수를 만들 수도 있다.
#include <Turboc.h>
void main()
{
int i; // 함수 범위
i=5;
{
int i; // 블록 범위
i=3;
printf("i=%d\n",i);
}
printf("i=%d\n",i);
}
3) 선언과 정의
이쯤에서 선언과 정의에 대해 구분해 보자. 아주 비슷한 용어인 것 같지만 달라도 한참 다르며 다소 헷갈리는 용어라 정리가 필요하다. 일단 도표로 선언과 정의의 특성을 정리해 보자.
|
|
역할 |
메모리 |
정보의 완전성 |
중복 가능성 |
|
선언 |
알린다. |
사용 안함 |
불완전해도 됨 |
가능 |
|
정의 |
생성한다. |
할당 |
항상 완전해야 함 |
불가능 |
선언과 정의의 대상이 되는 것에는 함수, 변수, 타입, 매크로, 태그 등 여러 가지가 있으나 주로 함수와 변수가 주 대상이다.
■ 선언(Declaration) - 컴파일러에게 대상에 대한 정보를 알린다. 함수가 어떤 인수들을 전달받으며 어떤 타입을 리턴하는지를 알리는 원형 선언이 대표적인 선언이다. 컴파일러에게 정보만 제공하는 것이므로 본체를 가지지 않으며 실제 코드를 생성하지도 않는다. 그래서 다음처럼 여러 번 중복되어도 상관없다.
int Max(int a, int b);
int Max(int a, int b);
물론 똑같은 내용을 일부러 이렇게 중복 선언할 경우는 없겠지만 헤더 파일을 여러 번 포함하다 보면 중복 선언될 경우가 있다. 이렇게 본의 아니게 중복 선언되더라도 문제는 없다. 단, 중복 선언할 경우 앞의 선언과 뒤의 선언이 달라서는 안된다. 앞에서는 int Max(...); 로 선언해 놓고 다시 선언할 때는 double Max(...)로 선언할 수는 없다.
■ 정의(Definition) - 대상에 대한 정보로부터 대상을 만든다. int i; 정의문에 의해 4바이트를 할당하며 int Max(int, int) { } 정의로부터 함수의 본체를 컴파일하여 코드를 생성한다. 정의는 변수의 타입, 함수의 인수 목록을 컴파일러에게 알려 주기도 하므로 항상 선언을 겸한다. 그래서 함수를 호출부보다 더 앞쪽에서 정의하면 컴파일러가 이 함수의 본체를 만들면서 모든 정보를 파악할 수 있으므로 별도의 원형 선언을 하지 않아도 된다.
정의는 실제 대상을 만들어 내기 때문에 중복되어서는 안된다. 전체 프로그램을 통해 단 한 번만 나타나야 하며 두 번 이상 중복할 필요도 없다. 만약 정의를 두 번 반복하면 컴파일러는 왜 똑같은 함수를 두 번 정의하느냐는 에러 메시지를 출력할 것이다.
이렇듯 선언과 정의는 분명히 다른 용어이지만 실제로는 명확하게 구분하지 않고 대충 사용하는 경향이 있다. 지역변수의 경우 정의와 선언이 완전히 일치하며 만든 영역에서만 사용하므로 별도의 선언을 할 수도 없고 할 필요도 없다. 그래서 지역변수는 정의만 가능한 대상이지만 일반적으로 "선언한다"라고 하지 "정의한다"라고는 하지 않는다. 전역변수의 경우는 int i;가 정의이고 extern int i;가 선언으로 분명히 구분되지만 관습적으로 전역변수 정의문인 int i; 도 선언문이라고 부른다.
매크로의 경우도 실제 메모리를 할당하는 것은 아니므로 선언이 맞지만 일반적으로 정의라고 표현한다. 매크로를 정의하는 명령어가 #define이지 #declare가 아닌 것만 봐도 그렇다. typedef에 의한 사용자 정의 타입도 키워드에 def라는 단어가 포함되어 있기는 하지만 원칙적으로 선언이라는 용어가 옳다. 그러나 표준 문서에서 조차도 typedef를 사용자 선언 타입이라고는 표현하지 않으며 타입을 정의한다고 표현한다. 구조체나 열거형의 태그는 주로 선언한다고 하지만 가끔 정의한다는 표현을 쓰기도 한다. 이렇듯 두 용어는 분명히 다르지만 실제로는 별 구분없이 사용되는 경향이 있다.
4) 설계 원칙
함수를 작성하는 문법과 호출하는 방법, 인수를 받아들이고 리턴하는 방법을 익히는 것은 그다지 어렵지 않다. 그러나 함수를 정말로 함수답게 잘 나누고 디자인하는 것은 무척 어렵고 단기간에 체득되지 않는다. 함수는 프로그램을 구성하는 단위로서 잘 나누어 놓으면 프로그램의 구조가 탄탄해지고 확장하기도 쉽고 재사용성도 좋아진다. 잘 짜여진 프로그램을 분석해 보면 함수의 분할 구조가 감탄스러울 정도로 잘 되어 있음을 볼 수 있고 그런 함수를 만드는 능력이 부러워지기까지 한다.
그러나 함수를 잘못 디자인하면 코드는 더 커지고 프로그램은 더 느려지며 조금이라도 수정하려면 어디를 건드려야 할지 판단하기 힘든 나쁜 구조가 만들어진다. 함수에 의해 코드는 꼬이기만 하고 엉망이 된 코드 사이로 버그가 창궐할 수 있는 환경만 만들어지니 아예 함수를 만들지 않느니만도 못한 상태가 되기도 한다.
프로그래밍에 처음 입문한 사람들에게 함수 디자인이라는 주제는 아주 어렵고 힘든 고비이다. 책을 읽어서 비법을 얻는 것은 불가능하고 잘 하는 사람에게 개인 지도를 받아도 어렵고 혼자서 연습해 보기는 더욱 더 어렵다. 함수 디자인은 오로지 많은 분석과 실습만으로 얻어지는 경험이다. 그래서 꾸준한 연습만이 해결책이다. 다음은 함수를 잘 만드는 기본적인 지침들이다.
함수명은 보통 동사와 목적어 그리고 약간의 수식어로 구성된다. GetScore, DrawScreen, TestGameEnd 등은 이름만으로 어떤 동작을 하는지 쉽게 알 수 있으므로 좋은 함수명이다. 동작이 좀 더 구체적이라면 GetHighestScore, GetAverageScore 등의 수식어를 붙이는 것도 좋다. 이런 이름은 무엇을 어떻게 하는지를 분명히 표현한다.
반면 Score, Draw, Test 따위는 점수나 그리기와 상관이 있는 동작을 하는 것 같아 보이기는 하지만 구체적으로 무엇을 어떻게 하는지를 표현하지 못하므로 좋지 않다. 함수를 만든 사람은 당장은 이 함수들을 이해할 수 있다 하더라도 조금만 시간이 지나면 함수의 본체를 다 읽어 봐야 무엇을 하는 함수인지 알 수 있으므로 코드를 유지 및 확장하기 어려워진다. 함수에 좋은 이름을 붙이는 것은 어려운 기술이 아니라 조금의 관심만 기울이면 누구나 할 수 있는 기술이며 이름을 구성하는 적절한 영어 단어만 잘 선정하여 조립하면 된다.
중복되는 회수에 상관없이 앞에서 이미 만들었던 코드와 비슷한 코드를 또 작성해야 한다면 일단 그 부분을 함수로 만들고 기존 코드를 함수 호출로 수정해야 한다. 즉 다음과 같이 구조를 만든다.
아니! 고작 두 번 중복되었을 뿐인데 이런 것들도 함수로 분리해야 한단 말인가 하는 생각이 들지도 모르겠다. 그 대답은 당연히 그렇다이다. 한 번 중복된 코드는 조만간 다시 필요해질 가능성이 아주 높다. 뿐만 아니라 십중팔구 그 코드는 잠시 후 확장되어야 한다. 그래서 중복이 발견되는 즉시, 그것이 단 두 군데 뿐이더라도 무조건 함수로 분리하는 습관을 가져야 한다. 네 번, 다섯 번 중복될 때 분리하겠다고 생각한다면 이미 프로그램은 엉망이 되어 가고 있는 것이다.
함 함수의 소스가 아주 길어져서 수백줄이 되면 그 많은 코드들의 어떤 부분이 어떤 작업을 하는지 얼른 파악되지 않는다. 게다가 다른 일을 하는 코드들이 한 곳에 섞여 있으면 필시 꼬이게 마련이며 이런 복잡한 코드는 대체로 메인 코드인 경우가 많다. 이 코드들의 그룹을 나누어 함수로 분리해 두면 메인 코드는 이 함수들을 조립하는 수준으로 간단해진다.
이렇게 분리되면 메인 코드를 읽기 쉬워지고 이미 완성된 코드들은 더 이상 신경쓰지 않아도 되는 이점이 있다. 또한 이 함수들이 현재 프로젝트에서는 반복되지 않더라도 다른 프로젝트에서는 재사용되기 쉽다.
이렇게 되면 이 함수를 호출하는 기존의 코드는 영향을 받지 않으면서 새로운 작은 단위의 작업을 호출할 수도 있게 된다.
void OutMessage(int x, int y, char *str, int len)
이 함수에서 메시지의 길이 len은 불필요한 인수이다. 세 번째 인수 str이 널 종료 문자열이라면 str로부터 길이를 계산할 수 있다. 물론 메시지의 일부만을 출력하는 기능이 있다면 이럴 때는 len이 필요할 것이다. 함수의 작업 결과는 가급적이면 리턴값으로 보고해야 하는데 설사 그 값을 호출원에서 사용하지 않는다 하더라도 일단 보고할 내용이 있다면 보고하는 것이 좋다.
여기서 논한 함수 설계에 대한 지침은 어디까지나 일반적인 참고사항일 뿐이다. 특수한 실무 환경에서는 이 지침과는 다르게 함수를 만들어야 하는 불가피한 경우도 존재한다. 이 지침이 함수 설계를 잘 하고 싶은 사람들에게 아주 중요한 내용인 것은 사실이지만 이 지침들을 몽땅 외운다고 해서 함수 설계 경험이 금방 늘어나는 것은 아니다. 마치 "여성의 마음을 사로잡는 100가지 비법"을 달달 외운다고 해서 사교계의 달인이 될 수 없는 것과 같다. 일단 이 권고안을 머리속에 새겨 두고 끊임없이 분석, 연습해 봐야 한다.
Boney James - Hypnotic
Doobie brothers
Alex Bugnon - Sara Smile
Renato Falaschi - Travelling Lite
snake davis
Max Bennett
Steve Cobb
Norman Brown
Urban Knights - sly
Blake Aaron
Down To The Bone - Glow
Gerald Albright
Voodoo Funk Project - Black Magic
Jorge Dalto - Stella By Starlight
bob james - Trade Winds
Jeanne Ricks - Simple Pleasure
Kim Waters - Happy Feeling
Weather Report - Birdland
Alexander Young - So Special
Doobie brothers
Alex Bugnon - Sara Smile
Renato Falaschi - Travelling Lite
snake davis
Max Bennett
Steve Cobb
Norman Brown
Urban Knights - sly
Blake Aaron
Down To The Bone - Glow
Gerald Albright
Voodoo Funk Project - Black Magic
Jorge Dalto - Stella By Starlight
bob james - Trade Winds
Jeanne Ricks - Simple Pleasure
Kim Waters - Happy Feeling
Weather Report - Birdland
Alexander Young - So Special
'etc' 카테고리의 다른 글
| xcopy 통째로 복사 (0) | 2020.09.16 |
|---|---|
| Excel 창 두개 띄우기 (0) | 2011.12.20 |
| 깡통파일(더미파일) 만들기 (0) | 2010.09.01 |
| Source Insight 3.5 떠있는 창 10개로 제한하기 (0) | 2010.07.09 |
| SourceInsight 한글 주석 깨지지 않게하기 (0) | 2010.07.09 |
1. 함수의 구성 원리
1) 함수
사용자 정의 함수를 만드는 기본 형식은 다음과 같다.
type name(인수 목록)
{
함수의 본체
}
■ name : 함수의 이름이며 이 이름을 통해 함수를 호출한다. 함수의 이름도 명칭(Identifier)이므로 명칭을 만드는 규칙대로 기억하기 쉽고 의미를 잘 표현할 수 있는 이름을 주는 것이 좋다. 점수를 출력하는 함수라면 PrintScore, 게임을 끝내는 함수라면 EndGame, 합계를 구하는 함수라면 GetSum 같은 이름을 붙이면 된다.
■ 인수 목록 : 함수가 해야 할 일의 세부 사항을 지정하며 함수의 작업거리라고 할 수 있다. 함수는 고유의 기능을 가지고 있고 호출부에서는 이 기능을 사용하기 위해 함수를 호출하는데 이때 함수에게 일을 시키기 위해서는 작업에 필요한 값을 전달해야 한다. 함수의 동작에 필요한 인수는 없을 수도 있고 여러 개일 수도 있는데 인수 목록에 필요한 인수의 타입과 이름을 밝힌다.
예를 들어 점수를 화면으로 출력하는 PrintScore 함수의 경우 출력할 현재 점수가 몇점인가를 가르쳐 주어야 하며 이런 정보가 인수로 전달된다. 만약 점수값 하나만 인수로 전달받는다면 PrintScore(int Score) 식으로 점수를 전달받을 것이다. printf는 서식 문자열과 출력할 값을 인수로 전달받으며 gotoxy는 이동 좌표를, delay는 지연시간을 전달받는다. 인수는 필요한만큼 사용할 수 있으며 개수의 제한은 없다. 필요하다면 점수를 출력할 좌표나 점수의 출력 형태 등도 인수로 전달받을 수 있다.
■ type : 함수가 리턴하는 값의 데이터형이며 함수의 작업 결과라고 할 수 있다. 함수는 고유의 작업을 실행하고 그 결과를 호출원에게 다시 돌려 준다. 예를 들어 합계를 구하는 함수 GetSum은 자신이 구한 합계를 호출원에게 보고하는데 이때 돌려주는 값의 타입이 바로 함수의 타입이다. 정수형 값을 리턴한다면 int, 실수형 값을 리턴한다면 double이라고 타입을 써 준다. getch 함수는 입력된 문자값을 리턴하며 wherex, wherey는 커서 좌표를 조사한다. 단순히 어떤 기능만 수행하는 함수라면 리턴하는 값이 없을 수도 있는데 이런 함수를 void 함수라고 한다.
■ 본체 : { } 괄호안에 실제 함수의 코드가 위치한다. 이 블록 안에 함수의 고유 기능을 수행하는 코드를 작성하면 된다. PrintScore 함수의 본체에는 인수로 전달된 점수값을 printf 함수로 출력하는 코드가 작성될 것이다.
2) 인수
인수(Parameter)는 호출원에서 함수에게 넘겨주는 작업 대상이라고 할 수 있다. 두 함수 사이의 정보 교환에 사용되므로 매개 변수(Argument)라고도 한다. Max 함수의 경우 두 정수값 중 큰 값을 선택하는 기능을 하므로 대상이 되는 두 정수값을 전달받아야 하며 그래서 int a, int b를 인수 목록에 적어 주었다. 다음은 여러 가지 함수의 인수 예이다.
▶ (x,y) 위치에 점수 Score를 출력하는 함수 : PrintScore(int x, int y, int Score)
▶ 실수 x의 제곱근을 구하는 함수 : GetSqrt(double x)
▶ 문자열에서 공백의 개수를 조사하는 함수 : GetSpaceNum(char *str)
작업 대상을 따로 전달받을 필요가 없다면 인수를 전혀 사용하지 않을 수도 있다. 예를 들어 화면을 지우는 clrscr 함수는 어떤 동작을 할 것인지 이미 정의되어 있으며 화면을 지우는데 별다른 지시 사항이 없으므로 별도의 인수를 전달받지 않는다. 인수가 없는 함수는 인수 목록을 비워 두거나 아니면 인수를 받지 않는다는 것을 분명히 표시하기 위해 인수 목록에 void라고 적는다.
clrscr();
clrscr(void);
인수는 형식인수와 실인수로 구분되는데 함수의 인수 목록에 나타나는 인수를 형식 인수라고 하며 함수 호출부에서 함수와 함께 전달되는 인수를 실인수라고 한다.
형식 인수는 호출원에서 전달한 실인수값을 잠시 저장하기 위한 임시 저장 장소이므로 어떤 이름이든지 사용해도 상관없다. 자신에게 전달된 인수값을 형식 인수에 잠시 대입해 놓고 함수 본체에서는 형식 인수로 호출원으로부터 전달된 실인수값을 읽기만 하면 된다. Max 함수는 다음과 같이 작성해도 완전히 동일하다.
int Max(int num1, int num2)
{
if (num1 > num2) {
return num1;
} else {
return num2;
}
}
호출원에서 전달받은 값을 이 함수내에서 num1, num2로 부르겠다는 뜻이다. Max 함수가 이렇게 정의되어 있고 main 에서 Max(a,b)를 호출했다면 형식 인수 num1이 실인수 a의 값을 가지게 되고 형식인수 num2는 실인수 b의 값을 가지게 될 것이다. 인수 전달은 일종의 대입 연산이며 함수 호출 과정에서 a, b의 값이 num1, num2로 대입된다. Max 함수는 전달받은 형식인수값의 대소를 판단하여 더 큰 수를 리턴하기만 하면 된다. 다음 예제는 두 정수의 값을 더하는 함수 Add를 정의한 것이다.
3) return
인수가 호출원으로부터 전달되는 작업 대상이라면 리턴값은 함수가 호출원으로 돌려주는 작업 결과이다. 앞에서 이미 봤지만 함수가 결과를 리턴할 때는 return 문을 사용한다. return문의 기능은 다음 두 가지이다.
우선 가장 일반적인 기능은 함수의 결과값을 호출원으로 돌려주는 것이다. return 예약어 다음에 리턴하고자 하는 값을 써 준다. Max 함수의 경우 a, b값의 대소에 따라 return a나 return b 명령으로 a나 b의 값 중 하나를 리턴하며 Add 함수는 ttt와 ddd를 더한 결과값을 리턴한다.
함수는 자신에게 맡겨진 임무대로 계산을 수행하여 그 결과를 호출원으로 리턴하며 호출원에서는 함수가 리턴한 값을 함수의 결과값으로 취한다. 함수가 어떤 값을 리턴할 것인가는 함수의 타입으로 이미 정의되어 있으므로 미리 정해진 타입의 값을 리턴하면 된다. Max와 Add는 모두 정수형 값을 리턴하도록 정의되었다.
호출원에서는 타입만 맞다면 함수가 리턴하는 값을 곧바로 사용할 수 있다. 즉, int 타입이 올 수 있는 곳이라면 int 타입을 리턴하는 함수도 항상 올 수 있다. Max 함수는 정수값을 리턴하므로 m=Max(a,b) 구문으로 Max 함수가 리턴하는 값을 정수형 변수 m에 대입할 수 있으며 Add 함수가 리턴하는 정수값을 printf의 %d 서식과 대응시킬 수도 있다.
함수는 단 하나의 유일한 결과를 리턴하기 때문에 타입만 맞다면 수식내에서도 바로 사용할 수 있다. d=Add(Max(a,b),c) 식은 a와 b중 큰 값과 c를 더한 값을 d에 대입한다. Max가 리턴하는 값이 정수형이므로 이 함수의 호출 결과를 Add 함수의 첫 번째 인수로 사용할 수 있고 Add가 더한 값을 정수형 변수 d에 대입할 수 있다. 함수는 한 번에 하나의 리턴값만 돌려줄 수 있기 때문에 타입만 맞다면 수식내에서 함수를 바로 쓸 수 있는 것이다. 다음 함수 호출도 모두 적법하다.
gotoxy(Max(a,b),Add(c,d));
Add(Add(Add(Add(1,2),3),4),5);
두 번째로 return 문은 결과를 돌려주는 것 외에 함수를 강제 종료시키는 기능을 한다. 함수 실행중에 return문을 만나면 함수의 뒷부분이 남아있건 말건 무조건 함수를 종료하고 호출원으로 돌아가 버린다. return문이 함수의 결과값을 돌려주는 명령인데 결과값을 돌려 주는 시점이 함수의 임무가 끝난 시점이므로 더 이상 함수의 나머지 부분을 실행할 필요가 없다.
4) void형
함수는 작업한 결과를 리턴값으로 돌려줄 수 있는데 모든 함수가 리턴값을 가지는 것은 아니다. 리턴할 값이 없는 함수도 있는데 이런 함수를 void형 함수라 한다. 정수형 값을 리턴하면 정수형 함수, 실수형 값을 리턴하면 실수형 함수 등으로 함수가 리턴하는 값의 데이터형이 곧 함수의 타입(type)이 되는데 void형 함수는 아무런 값도 리턴하지 않는 함수다.
단순히 "삐" 하는 효과음을 낸다든가, 미리 정해진 메시지를 출력한다든가 하는 함수들은 특별히 호출원으로 돌려줄 값이 없다. 이런 함수를 정의할 때는 함수 타입에 void라고 적는다. void형 함수는 내부적으로 작업만 할 뿐이지 계산 결과를 리턴하지 않으므로 호출원에서는 함수를 호출만 하며 리턴값을 대입받거나 사용하지 말아야 한다.
5) 함수의 다른 이름
■ 함수(function) : 특정 계산을 수행하며 리턴값이 있다. 반드시 수식내에서만 사용할 수 있으며 함수 단독으로 문장을 구성할 수 없다. 이 경우는 수학적 의미의 함수와 거의 유사하므로 적합한 용어 사용예라 할 수 있다.
■ 프로시저(procedure) : 특정 작업을 수행하며 리턴값이 없다. 리턴값이 없기 때문에 수식내에서는 사용할 수 없으며 단독으로 문장을 구성할 수는 있다. C의 void 함수가 이에 해당한다.
C의 함수는 파스칼의 함수와 프로시저에 해당하는 특성을 모두 가진다. 리턴값이 있을 수도 있고 없을 수도 있으며 모든 함수는 단독으로 사용할 수 있다. 파스칼은 형태에 따라 함수와 프로시저를 엄격하게 구분하여 실수를 방지하지만 C언어는 특별한 구분이 없으므로 융통성이 있다. 다음은 다른 언어와 구분되는 C 함수의 특징들이다.
① 함수끼리는 서로 평등한 관계에 있으며 상호 수평적이다. 즉, 함수끼리 언제나 호출 가능하다는 뜻이며 한 함수가 다른 함수에 예속되지 않는다. 반면 파스칼은 함수 내부에 지역 함수를 정의할 수 있어 함수끼리 수직적인 계층을 이룰 수 있다.
② 함수 중에서 가장 기본이 되는 함수를 main이라고 하며 프로그램의 시작점이 된다. 그러나 main이 다른 함수들과 특별히 다르지는 않으며 다만 프로그램의 실행 시작점이라는 것만 조금 특수할 뿐이다.
③ 리턴값은 있을 수도 있고 없을 수도 있다. 리턴값이 있는 함수는 리턴 타입을 가지며 그렇지 않은 함수는 void형으로 선언하면 된다.
④ 항상 단독으로 문장을 구성할 수 있다. 리턴값이 없는 함수는 단독으로만 사용할 수 있고 리턴값이 있는 함수는 수식 내에서 쓸 수도 있고 단독으로 쓸 수도 있다. 값을 리턴하는 함수라고 해서 반드시 리턴 값을 대입받거나 수식내에서만 써야 하는 것은 아니며 리턴값을 버리는 것이 가능하다. printf함수도 출력한 문자의 개수를 리턴하며 에러 발생시 음수를 리턴하는데 에러가 발생하는 경우가 거의 없고 출력 길이에도 특별한 관심이 없으므로 보통 단독으로 사용된다.
⑤ 값에 의한 호출 방식을 사용한다. 실인수가 형식인수에 대입될 때 항상 값이 대입된다는 뜻이다. 호출 방식에 대해서는 잠시 후 따로 연구해 볼 것이다.
2. 헤더 파일
1) 함수의 원형
함수의 원형을 이해하기 위해서는 C 컴파일러의 컴파일 방식에 대해 알아야 한다. 프로그래밍 언어는 해석 방식에 따라 인터프리터 방식과 컴파일 방식으로 나누어지는데 컴파일 방식이 훨씬 더 성능이 좋기 때문에 대부분의 언어가 컴파일 방식을 사용한다. C언어도 물론 컴파일 방식을 사용한다.
컴파일 방식은 소스를 읽어 기계어로 한꺼번에 번역하는 방식인데 번역을 몇 번에 나누어 하느냐에 따라 1패스, 2패스 등으로 구분된다. 한 번 죽 읽어서 번역을 다 해 내면 1패스 (one pass)방식이라고 하며 한 번 읽어서 컴파일 준비를 한 후 다시 읽으면서 기계어 코드로 바꾸는 방식을 2패스 방식이라고 한다. 2패스 방식의 대표적인 예가 어셈블러인데 소스상의 위치를 나타내는 레이블을 실제 번지로 바꾸기 위해 처음부터 끝까지 소스를 읽어 레이블의 번지를 미리 파악한 후 다시 처음부터 읽으면서 기계어 코드로 번역한다. 어셈블러는 이런 식으로 소스를 두 번 읽지 않으면 컴파일이 불가능하다.
3패스 방식을 채택하는 언어도 있고 디스 어셈블러들은 5패스 방식까지도 사용한다. 언어가 복잡해질수록 패스 수가 늘어나며 사용하는 메모리는 많아지고 컴파일 속도는 떨어진다. 초기의 C 컴파일러들은 컴파일 속도를 높이기 위해 통상 1패스 방식을 많이 채택했었다. C는 다른 언어보다 문법 구조가 복잡해서 컴파일 속도가 느린 편이라 패스를 여러 번 할 수가 없었다. 그래서 C 소스는 컴파일러에 의해 읽히는 족족 기계어로 번역된다.
물론 최근의 C컴파일러들은 1패스가 아닌 것들도 있지만 초기의 컴파일러들이 1패스 방식으로 작성되었기 때문에 C표준은 이런 컴파일러를 위해 한 번에 소스를 읽을 수 있는 장치를 마련할 필요가 있었다. 이러한 C의 1패스 방식 때문에 함수의 원형이라는 것이 필요하다. 원형(ProtoType)이란 함수에 대한 정확한 정보라는 뜻이며 리턴 타입, 함수 이름, 인수 리스트 등의 정보들로 구성된다.
원칙적으로 함수는 사용되기 전에 미리 그 형태를 컴파일러가 알 수 있도록 해야 하는데 그 방법이 바로 원형(ProtoType)을 선언하는 것이다. 함수의 원형을 미리 선언해 두면 본체는 뒤쪽에 있더라도 함수 호출부에서 이 명칭이 함수이고 어떤 인수를 요구한다는 것을 미리 알 수 있게 된다. 이렇게 함수의 정보를 미리 컴파일러에게 알려 주는 것을 "원형을 선언한다"라고 한다.
int Max(int a, int b); // 원형 선언
void main() {
함수의 원형은 컴파일러에게 함수에 대한 정보를 제공하기 위해 작성한다. 그래서 함수의 본체는 적지 않으며 리턴 타입, 함수 이름, 인수 목록만 적는다. 함수를 정의하는 형식에서 본체를 빼고 뒤에 세미콜론을 붙이면 이것이 함수의 원형이다. 원형 선언 자체도 하나의 문장이므로 세미콜론은 반드시 있어야 한다.
함수를 정의하는 형식에서 함수 이름이 포함된 첫 번째 줄만 옮겨 적고 뒤에 세미콜론을 붙이면 이것이 함수의 완전한 원형이다. Max 함수의 완전한 원형은 int Max(int a, int b);가 된다. 이때 함수의 원형에 적는 형식 인수의 이름은 사실 아무 의미가 없다. int Max(int kkk, int mmm); 이라고 써도 결과는 완전히 동일하다. 왜냐하면 형식인수란 함수의 본체내에서 호출원으로부터 전달된 값을 참조하기 위해 사용하는 것인데 원형 선언은 본체를 가지지 않으며 형식 인수를 사용하지 않기 때문이다.
그러나 인수들의 타입은 아주 중요한 의미가 있다. int Max(int a, int b); 원형은 이 함수의 이름이 Max이고 정수형 값을 리턴한다는 것 외에 두 개의 정수를 인수로 취한다는 정보를 담고 있다. 컴파일러는 이 원형을 미리 기억하고 있다가 혹시 사용자가 Max(1, 3.14) 같이 실수를 전달하면 소수점 이하가 잘린다는 경고를 출력하거나 Max(2,"name") 같이 변환할 수 없는 인수일 경우는 에러로 처리한다. 즉, 원형 선언이란 컴파일러에게 "혹시 내가 실수를 하면 좀 알려 줘"하고 요청해 놓는 것이다.
함수의 원형에서 형식 인수의 이름은 의미가 없기 때문에 형식 인수를 생략하는 간략한 원형 선언 방식도 허용된다. 인수 리스트에서 형식 인수 이름은 빼 버리고 인수의 타입만 적는 방식인데 Max 함수의 간략한 원형은 int Max(int,int);가 된다. 이 원형만으로도 컴파일러는 Max 함수에 대한 모든 정보를 다 알 수 있다.
이 외에 구형 C 컴파일러는 인수 리스트를 생략하는 int Max(); 같이 더 간략화된 형식도 지원했었으나 요즘의 C++ 컴파일러들은 인수 리스트의 생략은 허용하지 않는다. 다음에 배우게 되겠지만 C++은 인수 목록이 다르면 다른 함수로 취급하는 다형성을 지원하기 때문이다. 그래서 함수의 원형은 다음 두 가지 형식으로 쓸 수 있다.
int Max(int a, int b); // 완전한 원형 - 형식 인수명도 적어준다.
int Max(int, int); // 간략한 원형 - 인수의 타입만 밝힌다.
어떤 방식으로 원형을 선언하는가에 따른 차이점은 거의 없다. 어차피 컴파일러는 형식 인수의 이름 따위에는 전혀 관심이 없기 때문이다. 그래서 메모리나 하드 디스크값이 비쌌던 과거에는 간략한 형식의 원형을 많이 사용했었고 요즘도 이런 형식을 즐겨 쓰는 사람들이 많다. 의미도 없는 형식 인수명을 일일이 타이프하는 것도 꽤 성가신 일이기 때문이다.
하지만 최근에는 가급적이면 함수의 원형을 완전하게 적는 것이 더 권장된다. 형식 인수의 이름이 컴파일러에게는 아무 도움이 되지 않지만 함수를 사용하는 사람에게는 도움이 되기 때문이다. 예를 들어 화면에 원을 그리는 DrawCircle이라는 함수가 있다고 하자. 아마 이 함수의 원형은 다음과 같이 작성될 것이다.
void DrawCircle(int x, int y, int radius);
별다른 설명이 없더라도 이 원형으로부터 첫 번째, 두 번째 인수가 원의 중심점이고 세 번째 인수가 반지름이라는 것을 직관적으로 알 수 있다. 만약 간략한 형태로 void DrawCircle(int, int, int); 와 같이 써 버리면 이 함수를 사용하는 사람은 함수의 본체를 보거나 레퍼런스를 참조해야만 인수들의 정확한 의미를 알 수 있을 것이다. 원형에 포함된 형식 인수의 이름은 주석보다 더 좋은 참고 정보가 되므로 가급적이면 인수의 의미를 정확하게 전달할 수 있는 이름을 적어 놓는 것이 좋다.
표준 함수의 원형은 사용자에게 가급적이면 많은 정보를 제공하기 위해 모두 완전한 형태로 작성되어 있는 경우가 많다. 컴파일러에 따라서는 간략한 원형을 사용하는 것도 있다. 사용자 정의 함수들도 특별한 이유가 없는 한 완전한 형태로 적는 것이 좋다.
3) 헤더 파일
표준 함수의 원형을 미리 작성해 놓은 것을 헤더 파일(Header File)이라고 하며 stdio.h가 대표적인 헤더 파일이다. #include문은 헤더 파일을 소스 안으로 읽어 들이는 역할을 하므로 #include <stdio.h>명령에 의해 stdio.h에 선언된 모든 표준 함수의 원형을 공짜로 선언할 수 있게 된다.
4) 모듈
각각의 기능을 구현하는 함수 집합에 대해 모듈을 따로 만들 수 있으며 각 모듈은 개별적으로 컴파일되어 링커에 의해 하나의 실행 파일로 합쳐진다.
모듈 분할 컴파일 방식의 장점
(1) 컴파일 속도가 빠르다. 모듈을 작게 나눌 수록 컴파일 속도는 빨라진다.
(2) 분담 작업이 가능하다. 각 기능별로 분담이 가능하다.
(3) 프로젝트 관리가 쉽다. 소스 관리가 쉽다.
(4) 모듈을 재사용할 수 있다. 다른 프로젝트에 공유가 가능하다.
5) 모듈 예제
#include <Turboc.h>
void BoxMessage(char *str);
void main()
{
BoxMessage("박스를 그리고 그 안에 문자열을 출력한다.");
BoxMessage("전달된 문자열의 길이에 적당한 박스를 스스로 계산한다.");
BoxMessage("신기하군");
}
void BoxMessage(char *str)
{
int i;
int len;
len=strlen(str);
puts("");
for (i=0;i<len+4;i++) {
putch('-');
}
puts("");
printf("| %s |\n",str);
for (i=0;i<len+4;i++) {
putch('-');
}
puts("");
}
3. 함수 호출 방식
인수란 호출원에서 함수에게 일을 시키기 위한 정보인데 인수를 어떻게 전달하는가에 따라 값 호출(call by value) 방식과 참조 호출(call by reference) 방식이 있다. 인수를 넘기는 방식에 따라 실인수의 값이 변경되는가 아닌가의 차이점이 있다. 다소 어려울 수도 있지만 함수를 이해하는데 아주 중요한 내용이므로 잘 알아 두도록 하자.
1) 값 호출 (call by value)먼저 값 호출에 대해 알아보자. 값 호출 방식이란 실인수의 값이 형식 인수로 전달되는 방식이다. 다음 예제의 plusone 함수는 하나의 정수값을 전달받아 그 값에 1을 더한 값을 리턴한다.
j=plusone(i);
int plusone(int a)
{
a=a+1;
return a;
}
int plusone(int a)
{
a=a+1;
return a;
}
값을 복사해서 넘긴다라고 생각하면 쉽겠다.
2) 참조 호출 (call by reference)
값 호출과 참조 호출의 또 다른 차이점은 실인수로 상수를 전달할 수 있는가 하는 점이다. 값 호출 방식은 값을 전달하기 때문에 plusone(5)와 같이 상수를 실인수로 사용할 수 있다. i든 k든 5나 3이든 값을 가지기만 하면 형식인수 a가 이 값을 대입받을 수 있다. 심지어 i*k+1같은 수식도 계산된 후에는 값으로 평가되므로 이 값을 전달할 수 있다. 그러나 참조 호출은 번지를 전달하기 때문에 번지를 가지는 변수만 사용할 수 있으며 상수는 사용할 수 없다. 상수는 메모리를 점유하고 있지 않기 때문에 번지가 없다. 즉, 상수는 좌변값이 아니며 참조 호출 함수의 실인수로는 좌변값만 사용할 수 있다.
만약 plusref(&5)와 같이 상수의 번지를 넘기고 싶다고 해 보자. 5라는 상수는 좌변값이 아니므로 &5라는 표현부터가 벌써 잘못된 것이다. 5는 메모리에 저장된 값이 아니므로 번지가 없고 상수 5는 어디까지나 상수 5일 뿐이지 어떤 방법을 쓰더라도 이 값은 6이나 4가 될 수는 없다.
plusref(&i);
void plusref(int *a)
{
*a=*a+1;
}
3) 출력용 인수
gotoxy(10,20);
plusone(i);
printf("The Result is %d",k);
이 호출문들에서 사용된 모든 인수가 바로 입력용 인수들이다. 함수로 입력되는 실체는 값이므로 상수를 바로 쓸 수도 있다. 하지만 초기화되지 않은 변수를 쓰는 것은 일반적으로 경고 처리되는데 다음 호출문을 보자.
int i,j;
j=plusone(i);
i를 선언만 하고 바로 plusone 함수에게 이 값을 전달했다. i를 선언만하고 초기화하지 않았으므로 이때 plusone이 받게 되는 값은 쓰레기값이며 컴파일러에 의해 경고로 처리된다. 알지도 못하는 값에 대해 어떤 동작을 하려고 했으므로 정상적인 코드가 아니라는 뜻이며 이대로 내버려 두면 골치아픈 버그의 원인이 되기도 한다. 입력용 인수는 함수로 전달되기 전에 반드시 원하는 값으로 초기화되어야 한다.
int i;
scanf("%d",&i);
정수값 하나를 입력받기 위해 i변수를 선언하고 이 변수의 번지를 scanf 함수에게 전달했다. 참조 호출이기 때문에 상수는 사용할 수 없고 반드시 변수만 사용할 수 있다. 또한 입력되는 값이 아니므로 초기화할 필요가 없으며 위 코드는 경고없이 정상적으로 컴파일된다. scanf는 i의 값을 입력받아 어떤 동작을 하는 것이 아니라 먼저 어떤 동작을 한 후 그 결과를 i에 대입하기 위해 이 변수의 번지를 전달받았다. 그래서 scanf의 인수는 출력용이다.
함수가 호출원으로 작업 결과를 돌려주는 일반적인 방법은 리턴값을 사용하는 것이지만 이런 식으로 출력용 인수를 사용하여 리턴값을 돌려줄 수도 있다. 리턴값은 단 하나밖에 돌려줄 수가 없지만 출력용 인수를 사용하면 여러 개의 값을 동시에 돌려줄 수 있다는 이점이 있다. 예를 들어 게임의 캐릭터 좌표를 조사하는 함수를 만든다면 다음과 같이 만들어야 한다.
void GetCharacterPos(int *x, int *y);
평면상의 좌표는 (x,y) 두 개의 정수값으로 표현되기 때문에 리턴값으로는 이 좌표를 돌려줄 수 없으며 참조 호출로 두 개의 정수값을 돌려 주도록 해야 한다. 함수의 리턴값이 하나밖에 없는 이유는 유일한 값을 리턴해야만 함수를 수식내에서 바로 사용할 수 있기 때문이다. 이 예에서처럼 여러 개의 값을 동시에 조사해야 하는 경우라면 출력용 인수를 사용하거나 아니면 구조체를 리턴하도록 해야 한다. 이 함수를 호출하려면 반드시 두 개의 변수를 선언해야 하며 수식내에서 바로 사용할 수도 없다.
출력용 인수와 다른 점은 입력을 겸하고 있기 때문에 반드시 초기화를 해야 한다는 점이다. 그러나 초기화하지 않고 전달할 경우 컴파일러가 이를 에러나 경고로 처리하지는 않는데 왜냐하면 이 인수가 출력용인지 입출력용인지는 형태상으로 구분되지 않기 때문이다. 하지만 초기화되지 않은 쓰레기값을 사용하면 당연히 원하는 결과는 나오지 않는다.
참조 호출 방식이므로 상수는 물론 사용할 수 없으며 변수만 사용할 수 있다. 입출력용 인수의 예는 그리 흔하지는 않지만 바로 앞에서 만들어 보았던 plusref 함수의 a 인수가 바로 입출력을 겸하는 인수이다. 이 함수는 a의 값을 입력으로 받아 들이기도 하며 이 값을 1 증가시켜 다시 a로 돌려 주기도 한다. 입력, 출력을 모두 겸하고 있으니 입출력용 인수라고 하는 것이다.
3. 전처리기 (PreProcessor)
1) #include
컴파일러는 #include 명령을 먼저 처리하여 헤더 파일을 모두 포함한 후에 컴파일을 시작한다. 그래서 #include <stdio.h> 명령을 소스 선두에 작성해 놓으면 stdio.h에 선언된 함수의 원형, 데이터 타입, 열거 상수 등을 공짜로 사용할 수 있는 것이다.
#include 명령을 쓰는 대신 헤더 파일의 내용을 복사하여 직접 소스에 붙여 넣어도 결과는 동일하지만 불편할 것이다. #include 명령으로 포함시키면 하나의 헤더 파일을 여러 소스에서 동시에 사용할 수 있으며 소스의 길이가 짧아져 관리하기에도 좋다. #include 다음에 포함할 파일의 이름을 적는데 사용하는 괄호에 따라 두가지 형태가 있다.
■ #include <file.h> : C에서 제공하는 표준 헤더파일을 포함시키고자 할 때 < > 괄호를 사용한다. 컴파일러의 옵션중에 표준 헤더 파일들이 어떤 디렉토리에 있는지를 기억하는 옵션이 있는데 비주얼 C++의 경우 도구/옵션/프로젝트/VC++ 디렉토리(6.0의 경우 Tools/Options/Directories) 대화상자에서 헤더 파일 디렉토리를 지정한다. < >괄호를 사용하면 표준 헤더 파일 디렉토리에서 지정한 파일을 찾는다.
■ #include "file.h" : 사용자가 직접 작성한 헤더 파일을 포함시키고자 할 때 " "괄호를 사용한다. 이 괄호를 사용하면 소스 파일과 같은 디렉토리에서 헤더 파일을 먼저 찾아 본다. 직접 만든 헤더 파일은 보통 소스와 같은 디렉토리에 두므로 이 괄호를 사용하면 된다.
괄호 형식에 따라 헤더 파일을 어디서 먼저 찾을 것인가의 검색 순서가 달라지는데 사실 두 괄호는 그다지 엄격하게 구분할 필요가 없다. " " 괄호를 사용했더라도 현재 디렉토리에 이 파일이 없으면 표준 헤더 파일 디렉토리도 검색하며 반대로 < > 괄호를 사용했더라도 현재 디렉토리도 같이 검색한다. 즉 #include "stdio.h"라고 할 경우 현재 디렉토리에 stdio.h가 있는지 보고 없다면 표준 헤더 파일 디렉토리도 검색하므로 결과는 마찬가지다.
괄호에 따라 결과가 달라지는 경우는 표준 헤더 파일 디렉토리와 현재 디렉토리에 같은 이름을 가지는 헤더 파일이 있을 경우인데 어떤 파일이 우선적으로 포함되는가만 다를 뿐이다. 이런 특수한 경우가 아니라면 굳이 괄호를 구분할 필요는 없다. 그러나 관행상 표준 헤더 파일은 < > 괄호를, 사용자 정의 헤더 파일은 " "를 사용하고 있으므로 이 관행을 지키는 것이 바람직하다.
#include 명령은 주로 헤더 파일을 포함시키기 위해 사용하지만 꼭 헤더 파일만 가능한 것은 아니다. 확장자가 cpp인 파일도 포함할 수 있으며 txt나 임의의 파일이라도 텍스트 파일이기만 하면 다 포함할 수 있다. 예를 들어 1000줄쯤 되는 아주 큰 배열 정의문이 있는데 이 정의문이 너무 길어 소스를 편집하기가 불편하다면 이 부분만 array.cpp로(또는 array.txt, array.inc) 따로 떼어 내고 주 파일에서는 #include "array.cpp"로 불러 오면 된다.
#include 다음의 파일명은 대소문자를 구분하지 않는다. C언어 자체는 대소문자를 구분하지만 윈도우즈의 파일 시스템이 대소문자를 구분하지 않기 때문에 #include <STDIO.H>라고 쓸 수도 있고 #include <stdio.h>라고 해도 문제가 없다. 물론 유닉스나 리눅스 환경에서는 대소문자가 구분되므로 가급적이면 원래 파일명과 똑같이 쓰는 것이 좋다.
#include 명령은 중첩 가능하다. 포함한 파일이 다른 파일을 포함하고 있다면 포함된 모든 파일이 주 파일로 읽혀진다. 예를 들어 A가 B를 포함하고 있는 상태에서 주 파일이 #include "A" 명령을 사용하면 A가 B까지 같이 가지고 주 파일에 포함된다.
2) #define#define전처리문은 매크로 상수를 정의하는데 기본 문법은 다음과 같다.
#define 매크로명 실제값
#define GAMETIME 240
다음은 #define 문으로 매크로 상수를 정의할 때의 일반적인 주의 사항이다. 상식적으로 쉽게 이해될 것이다.
① #define문은 전처리문이지 코드를 생성하는 명령이 아니다. 그래서 행 끝에 세미콜론은 붙이지 않는다. #define MACH 1200.0;이라고 써서는 안된다. 만약 이렇게 쓰면 세미콜론조차도 매크로의 실제값에 포함되어 버린다. #include는 물론이고 다음에 배울 모든 전처리문들도 세미콜론은 붙이지 않으며 주석을 제외한 다른 문장이 뒤따라 올 수 없다.
② 매크로의 이름도 일종의 명칭이기 때문에 명칭 규칙에 맞게 작성해야 한다. 중간에 공백이 들어간다거나 숫자로 시작한다거나 다른 명칭과 충돌해서도 안된다. 매크로 상수는 다른 명칭과 구분될 수 있도록 관습적으로 대문자를 사용하는 것이 일반적이다. NUM, MY_MACRO 등은 적법한 명칭이며 3RD는 숫자로 시작되었으므로 부적격하며 MY MACRO는 중간에 공백이 있으므로 매크로명으로 사용할 수 없다.
③ 매크로 이름에는 공백이 들어갈 수 없지만 매크로의 실제값은 공백을 가질 수 있다. #define 전처리문은 매크로를 실제값으로 단순 치환할 뿐이므로 공백이 있건 한글을 사용하건 전혀 상관하지 않는다. 다음은 자주 쓰는 메시지 문자열을 매크로로 정의한 것이다.
#define ERRMESSAGE "똑바로 하란 말이야"
문자열을 통째로 ERRMESSAGE라는 매크로 상수로 정의했으며 좀 어색해 보이지만 적법한 문장이다. 실제 코드에서 puts(ERRMESSAGE); 형식으로 사용하면 된다.
④ 문자열 상수내에 있는 매크로나 다른 명칭의 일부로 포함된 경우는 치환되지 않는다. #define HUMAN 5 라는 전처리문은 소스의 모든 HUMAN을 찾아 5로 치환할 것이다. 그러나 printf("I am a HUMAN"); 문장에 있는 HUMAN은 매크로 상수와 이름은 같지만 어디까지나 문자열일 뿐이므로 치환하지 않는 것이 합리적이다. HUMANNAME이라는 다른 명칭에도 HUMAN이라는 이름이 포함되어 있지만 분리된 명칭이 아니므로 5NAME으로 치환되지 않는다.
⑤ 매크로는 중첩 가능하다. 즉, 매크로 상수가 매크로 상수를 참조할 수 있다는 얘기다. 다음 예를 보자.
#define A 3
#define B (A*2)
A를 3으로 정의했고 B는 A에 2를 곱한 값으로 정의했으므로 6이 될 것이다. B가 A를 참조하고 있는 셈이다. 두 번 세 번 얼마든지 중첩할 수 있되 단 중첩되는 매크로가 먼저 정의되어 있어야 하므로 순서에 신경써야 한다.
⑥ 값을 가지지 않는 빈 매크로도 정의할 수 있다.
#define PROFESSIONAL
이 매크로는 값을 가지지 않으며 매크로 상수 자체만 존재할 뿐이다. 이렇게 값을 가지지 않는 매크로는 주로 조건부 컴파일 지시자와 함께 사용되며 존재하는가 아닌가만으로 의미를 가진다. 또한 아무 값도 가지지 않음을 명시할 때도 빈 매크로를 정의한다.
#define 전처리문의 동작이 단순하기 때문에 매크로 상수는 쉽게 이해가 갈 것이다. 그렇다면 매크로 상수를 어느 수준으로 사용할 것인가에 대해 생각해 보자. 모든 상수를 다 매크로 상수로 정의한 후 사용할 수도 있고 적당한 수준에서 상수를 직접 사용할 수도 있는데 이는 개인적인 취향에 따라 결정할 문제이다.
매크로 상수는 분명히 기억하기 쉽도록 해 주고 일괄적인 수정에 도움을 준다. 그러나 너무 남발하면 오히려 소스를 더 읽기 어렵게 만들 수도 있으며 기억력 보조에도 별 도움이 되지 못하는 경우가 있다. 다음 예를 보자.
3) 매크로 함수#define을 이용하여 다음과 같이 매크로 함수를 작성할 수는 있지만 컴파일이 진행될 때 각 매크로를 함수의 내용으로 그대로 치환하는 형식이라 효율적인 방법은 아니다.
#define dubae(i) i+i;
#define VALUE2 VALUE+100;
#define printmsg(x,y,str) { gotoxy(x,y); puts(str); }
4) C 프로그램의 구조
C프로그램은 대체로 다음과 같은 구조를 가진다고 했다. 물론 필요에 따라 순서를 조금씩 바꿀 수 있겠지만 여러 사람들이 오랫동안 C로 프로그래밍을 해 본 결과 이 구조가 가장 이상적이라는 것을 알게 되었으며 그래서 대부분의 C 소스는 이런 구조로 만들어진다. 처음 배울 때는 남들 하는대로 일단 따라하는 것이 좋다.
#include <...>
#define ...
함수의 원형
전역변수
void main()
{
코드
}
함수
함수
함수
제일 먼저 헤더 파일을 포함하는 #include 문이 오고 다음으로 매크로를 정의하는 #define이 온다. 그리고 이 프로그램이 사용하는 함수의 원형과 전역변수를 선언하고 main 함수가 가장 먼저 오며 main 함수 다음에 사용자 정의 함수를 작성한다. 이 방식대로 코드를 작성하면 제일 말썽이 없고 코드를 유지 보수하기에 편리하다.
출처: http://winapi.co.kr/instruction ; 명령어
|
명령어는 컴퓨터 프로그램이 주어진 컴퓨터 프로세서에게 내리는 명령이다. 최하위 계층에서, 각 명령어는 컴퓨터가 수행해야하는 물리적인 연산, 그리고 명령어 형태에 따라서는 그 명령어를 수행하는데 사용되는 데이터를 저장하고 있는 레지스터의 명세나, 그 명령어를 수행하는데 사용되는 데이터의 위치, 또는 데이터를 직접 또는 간접 참조하기 위한 메모리 내의 위치 등을 나타내는 0과 1의 연속이다. 컴퓨터의 어셈블러언어에서, 일반적으로 각 문장은 하나의 프로세서 명령어에 대응된다. 고급언어에서, 일반적으로 하나의 프로그램 문장은 컴파일 후에는 여러 개의 프로세서 명령어로 나뉘어진다. 어셈블러언어에서, "매크로 명령어"는 어셈블러 프로그램에 의해 처리되면서 여러 개의 명령어로 확장된다. |
'old > 용어정리' 카테고리의 다른 글
| IS (information system[s] or information services) ; 정보시스템 또는 정보서비스 (0) | 2010.11.18 |
|---|---|
| interoperability ; 상호 운용성 (0) | 2010.11.18 |
| internationalization ("I18N") ; 국제화 (0) | 2010.11.16 |
| I/O (input/output) ; 입출력 (0) | 2010.11.16 |
| heterogeneous ; 이종 (0) | 2010.11.15 |



