유니코드가 없었던 시기에는 한 데이터베이스에 중국어, 아랍어 등을 같이 저장할 수 없었기 때문에 해당언어를 지원하는 데이터베이스를 따로 구축했었다. 이렇게 할 경우 시스템 비용의 증가와 새로운 언어 추가 시의 비용, 전체 시스템의 통합된 정보를 조회의 어려움에 직면하게 되었고 하나의 Character Set으로 세계 각국의 언어를 표현할 수 있으면 좋겠다는 요구가 있어 유니코드가 탄생하게 되었다.
유니코드의 정의는 어떤 언어로 된 정보도 단일 Character Set으로 저장할 수 있는 국제적으로 부호화된 Character Set이다. 유니코드는 또한 platform, program, language에 관계없이 모든 character는 유일한 값을 가진다. 따라서 여러 나라 언어를 동시에 저장하고자 할 경우 유용하게 사용할 수 있다. .
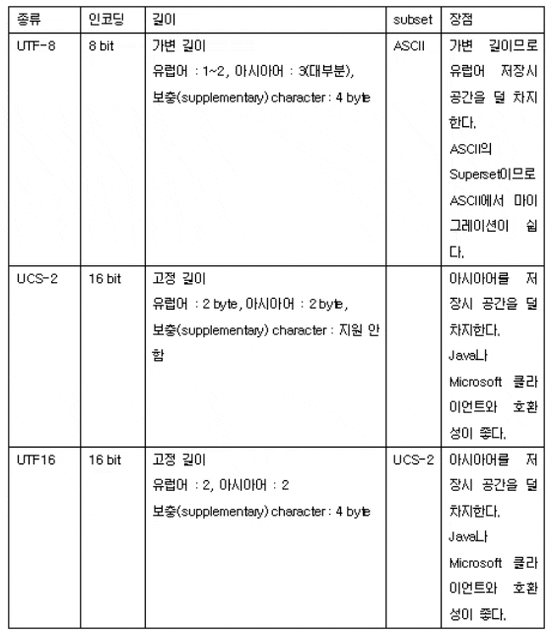
가변 길이는 언어마다 한글자가 차지하는 길이(byte)가 다르다는 것을 말하고, 고정 길이는 언어에 관계없이 한글자가 차지하는 길이는 동일하다는 것을 의미한다. 각 유니코드별 장점도 이러한 특성을 고려하면 쉽게 이해 할 수 있을 것이다. 대표적으로 사용되는 유니코드로는 UTF-8, UCS-2, UTF16가 있으며 각각의 특징과 장단점을 도표로 나타내면 다음과 같다.
'old > Mobile' 카테고리의 다른 글
| 플랫폼(Platform)과 프레임워크(Framework) 개념비교 (0) | 2010.05.10 |
|---|---|
| TCP/IP 프로토콜 아키텍처 (0) | 2010.05.10 |
| 포트(Port) 개념잡기 (0) | 2010.05.10 |
| 소켓통신 (TCP 통신과 UDP 통신 비교) (0) | 2010.05.10 |
| 스텁(Stub)과 스켈레톤(Skeleton) (0) | 2010.05.10 |



