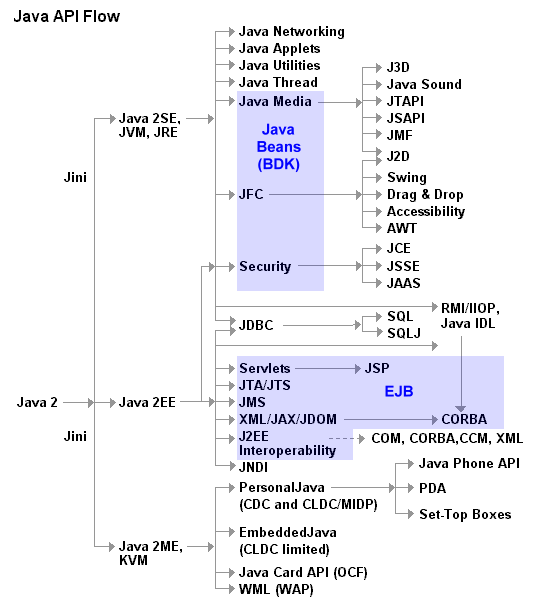
JNI(Java Native Interface)
플랫폼 독립성을 버리고, 기능을 취한다.
자바 프로그램을 작성하다보면, 부득이하게 시스템 의존적 코딩을 필요로 하는 때가 있다. 하지만, 자바로서는 그러한 욕구를 감당할 수는 없다. 따라서, 자바의 클래스 파일이 C/C++의 함수를 호출하여, 그 결과만 되돌려받게 하는 것도 한 방법이다. 그렇지만 이 자체로서 이미 플랫폼 독립적이라는 특성은 사라졌다고 볼 수밖에 없다.
프로그램 작성
첫째 단계, 자바 프로그램 작성
우선, Native접근이 필요한 메쏘드만 native 키워드를 사용해 구현하지 않은 채 그대로 두고, 나머지는 모두 구현한 후, 컴파일한다.
public class Hello {
public native void getHello();
static {
System.loadLibrary("hello");
}
public static void main(String[] args) {
new Hello().getHello();
}
}
javac Hello.java
public native void getHello() : getHello 함수가 native method라는 것을 의미한다.
static {
System.loadLibrary("hello");
}
이것은 공유 라이브러리를 실행시 로드하는 코드로 반드시 static 초기화에 포함되어야 한다. 이것은 플랫폼에 따라 다르게 행동하는데, 만일 Win32이면, hello.dll을, 솔라리스이면, libhello.so라는 이름의 라이브러리를 찾는다.
둘째 단계, C프로그램을 위한 헤더 파일 생성
javah와 -jni옵션을 이용하여, 헤더파일을 생성해 보자.
생성된 헤더 파일 Hello.h는 다음과 같다.
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class Hello */
#ifndef _Included_Hello
#define _Included_Hello
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: Hello
* Method: getHello
* Signature: ()V
*/
JNIEXPORT void JNICALL Java_Hello_getHello
(JNIEnv *, jobject);
#ifdef __cplusplus
}
#endif
#endif
여기서 생성된 함수 이름에 주목해 보자. '_'를 구분자로 크게 몇 부분으로 나뉘어져 있다.
- Java : 항상 앞에 붙는다.
- Hello : 클래스의 이름
- getHello : 메쏘드의 이름
셋째 단계, 함수를 구현한다.
HelloImpl.c라는 이름으로 함수를 구현해 보자.
#include <jni.h>
#include "Hello.h"
#include <stdio.h>
JNIEXPORT void JNICALL Java_Hello_getHello(JNIEnv *env, jobject obj)
{
printf("OOPSLA\n");
return;
}
넷째 단계, C파일을 컴파일하여, 공유 라이브러리를 생성한다.
이때, 비주얼 C++을 이용할 경우 다음과 같은 옵션을 준다.
cl /I본인의 자바 디렉토리)\include /I(본인의 자바 디렉토리)\include\win32 -LD HelloImp.c -Fehello.dll
솔라리스에서 컴파일할 경우 다음과 같은 옵션을 준다.
cc -G -I(자바 홈 디렉토리)/include -I(자바 홈 디렉토리)/include/solaris HelloImp.c -o libhello.so
마지막 단계, 프로그램을 실행한다.
실행 결과:
자바의 타입과 C++/C의 타입 매핑 문제
네이티브 메쏘드를 호출하는 것까지는 좋다. 하지만, 그 결과값이 있을 경우에는 타입의 괴리(Impedence)가 존재할 수밖에 없다. 따라서, jni.h에는 자바의 타입을 흉내낼 수 있는 여러 가지 타입을 정의해 놓았다.
Primitive Types
네이티브 메쏘드에서는 보통 자바의 타입 이름 앞에 j가 붙은 이름을 가진 타입을 사용함으로써, 마치 자바 프로그램을 작성하는 듯이 프로그램할 수 있다. 예를 들어, boolean은 jni.h에 jboolean이라는 이름의 타입과 매핑된다.
- jboolean : 자바의 boolean(8비트) - typedef unsigned char jboolean
- jbyte : 자바의 byte(8) - typedef signed char jbyte(WIN32의 경우이다. - System Dependent)
- jchar : 자바의 char(16) - typedef unsigned short jchar
- jshort : 자바의 short(16) - typedef short jshort
- jint : 자바의 int(32) - typedef long jint(WIN32의 경우이다. - System Dependent)
- jlong : 자바의 long(64) - typedef __int64 jlong(WIN32의 경우이다. - System Dependent)
- jfloat : 자바의 float(32) - typedef float jfloat
- jdouble : 자바의 double(64) - typedef double jdouble;
- void : 자바의 void
위의 리스트에서, 오른쪽은 실제 jni.h가 이 타입들을 어떻게 정의하고 있는지를 보여 준다. 여기서, jbyte, jint, jlong은 시스템에 따라 적용할 타입이 변경될 소지가 있으므로, WIN32의 경우, 자바디렉토리\include\win32\jni_md.h에 정의되어 있다. 솔라리스인 경우에는 참고로 다음과 같다.
#ifdef _LP64 /* 64-bit Solaris */
typedef int jint;
#else
typedef long jint;
#endif
typedef long long jlong;
typedef signed char jbyte;
객체 타입
이 경우에도 비슷하다. 일반 객체는 jobject타입으로 통용하고, 나머지 특수한 클래스에 대해 매핑되는 타입을 두기로 한다.
- jobject : 모든 자바 객체로 뒤에 나열된 모든 타입의 슈퍼 타입이다.
- jstring : 자바의 java.lang.String클래스이다.
- jclass : 자바의 java.lang.Class클래스이다.
- jarray : 자바의 배열이다.
- jthrowable ; 자바의 java.lang.Throwable 예외 사항이다.
배열
기타, 기본 타입의 배열을 위한 배열 타입도, 하나의 클래스로 정의되어 있다.
jbooleanArray;
jbyteArray;
jcharArray;
jshortArray;
jintArray;
jlongArray;
jfloatArray;
jdoubleArray;
jobjectArray;
함수와 메쏘드간의 인자 전달
문제는 jstring을 비롯한 타입들은 실제 printf문 같은 곳에서 직접 쓰일 수 없다는 것이다. 이것들은 다시, C/C++의 타입으로 변환되어 사용되어야 한다. 이것에 관한 여러 함수들이 JNIEnv라는 구조체에 정의되어 있다.
예를 들어, String객체를 C메쏘드에 넘기도록 앞의 Hello.java를 수정해 보자. 자바 소스는 단순히 선언을 바꾸는 것으로 끝난다.
재컴파일과, javah를 이용해 만든 새로운 헤더 파일을 이용해 HelloImpl.c를 새로 작성해 보면,
JNIEXPORT void JNICALL Java_Hello_getHello(JNIEnv *env, jobject obj,jstring name)
{
char *str_name = (*env)->GetStringUTFChars(env, name, 0);
printf("Hello %s\n",str_name);
(*env)->ReleaseStringUTFChars(env, name, str_name);
return;
}
이와 같이, JNIEnv의 멤버 함수로부터 도움을 받아야 한다.
이제 각 타입에 대해 인자 전달과 결과값 반환 방법을 알아 보자.
Primitive Types
기본 타입의 경우에는 다음과 같이 기존의 C/C++타입중 호환되는 타입의 재명명이므로, 그다지 인자 전달에 문제가 없다.
typedef unsigned char jboolean;
typedef unsigned short jchar;
typedef short jshort;
typedef float jfloat;
typedef double jdouble;
WIN32:
typedef long jint;
typedef __int64 jlong;
typedef signed char jbyte;
다만, boolean의 경우에는 true/false값이 다음과 같이 전달된다.
예를 들어, boolean타입의 인자를 주고, 반환받는 경우,
Hello.java:
Hello h = new Hello();
System.out.println("h.getBoolean(true) = "+h.getBoolean(true)); // 결과 : true
HelloImpl.c:
JNIEXPORT jboolean JNICALL Java_Hello_getBoolean(JNIEnv * env, jobject jobj, jboolean jbool)
{
......
return JNI_TRUE;
}
배열 타입
각 기본 타입에 따라 그 배열을 다룰 수 있는 배열 클래스가 제공된다.
모든 배열 클래스들은 jarray 클래스의 하위 클래스이다.
배열의 길이 파악
모든 배열의 길이를 알아낼 수 있는 함수는 다음과 같다.
jsize GetArrayLength(JNIEnv *, jarray array)
(jsize는 jint와 동일하다)
자바의 배열을 C의 배열로 변환하는 함수
각 타입마다 자바 타입의 배열을 C타입으로 변환시켜 주는 함수가 있다.
- jboolean * GetBooleanArrayElements(JNIEnv *env,jbooleanArray array, jboolean *isCopy)
- jbyte * GetByteArrayElements(JNIEnv *env,jbyteArray array, jboolean *isCopy)
- jchar * GetCharArrayElements(JNIEnv *env,jcharArray array, jboolean *isCopy)
- jshort * GetShortArrayElements(JNIEnv *env,jshortArray array, jboolean *isCopy)
- jint * GetIntArrayElements(JNIEnv *env,jintArray array, jboolean *isCopy)
- jlong * GetLongArrayElements(JNIEnv *env,jlongArray array, jboolean *isCopy)
- jfloat * GetFloatArrayElements(JNIEnv *env,jfloatArray array, jboolean *isCopy)
- jdouble * GetDoubleArrayElements(JNIEnv *env,jdoubleArray array, jboolean *isCopy)
정수의 경우를 예로 들어 보자.
jsize iSize = (*env)->GetArrayLength(env,jiarray);
jint *iArray = (*env)->GetIntArrayElements(env,jiarray,0);
for(i=0; i < iSize; i++) {
printf("iArray[%d] = %d\n",i,iArray[i]);
iArray[i]++;
}
(*env)->ReleaseIntArrayElements(env,jiarray,iArray, 0);
자바의 배열을 JNI에서 사용할 경우, 이것은 현재의 실행 루틴을 수행하는 쓰레드가 이 배열 객체에 대해 PIN 연산을 수행하거나, 아니면 전체의 로컬 복사본을 사용하게 되는 것이다. 이로 인해, 이 연산의 반대 급부로 반드시 UNPIN연산에 해당하는 ReleaseIntArrayElements가 불려지는 것이 좋다.
- void ReleaseBooleanArrayElements(JNIEnv *env,jbooleanArray array, jboolean *elems, jint mode)
- void ReleaseByteArrayElements(JNIEnv *env,jbyteArray array, jbyte *elems, jint mode)
- void ReleaseCharArrayElements(JNIEnv *env,jcharArray array, jchar *elems, jint mode)
- void ReleaseShortArrayElements(JNIEnv *env,jshortArray array, jshort *elems, jint mode)
- void ReleaseIntArrayElements(JNIEnv *env,jintArray array, jint *elems, jint mode)
- void ReleaseLongArrayElements(JNIEnv *env,jlongArray array, jlong *elems, jint mode)
- void ReleaseFloatArrayElements(JNIEnv *env,jfloatArray array, jfloat *elems, jint mode)
- void ReleaseDoubleArrayElements(JNIEnv *env,jdoubleArray array, jdouble *elems, jint mode)
이 외에도 다음과 같은 함수들이 있다.
- jdoubleArray NewDoubleArray(jsize len)를 비롯해 각 기본 타입마다 새로운 자바 배열을 생성할 수 있다.
- void GetBooleanArrayRegion(jbooleanArray array, jsize start, jsize len, jboolean *buf)를 비롯해 각 기본 타입마다 Sub배열을 획득할 수 있는 함수가 제공된다.
자바 객체의 사용
네이티브 코드 내에서 자바 객체를 사용할 수도 있다. 즉 콜백과 비슷한 형식을 지원한다. private영역까지 접근할 수 있다.
자바 객체의 클래스 정보 얻기
일단, 인자로 넘겨지는 자바 객체에 대한 클래스 정보를 획득하는 함수가 제공된다.
jclass cls = (*env)->GetObjectClass(env, jobj);
여기서 주의할 것은 반환값으로 돌아오는 cls의 레퍼런스값은 오직 이 네이티브 메쏘드가 수행이 끝날 동안에만 유효하다는 것이다.
자바 객체 및 클래스 타입의 래퍼런스는 네이티브 메쏘드 실행시마다 결정되므로, 한 번 실행해 얻은 레퍼런스를 다음번 메쏘드에서 다시 사용하려는 것은 잘못된 것이다.
따라서, 원칙적으로 객체 레퍼런스 변수를 전역 변수로 할당하는 것은 위험한 일이다. 하지만, 꼭 허용되지 않는 것은 아니다. 전역 레퍼런스로 지정해 줄 수 있는 함수가 있다.
jobject NewGlobalRef(JNI_Env* env, jobject lobj)
네이티브 코드를 호출한 객체의 메쏘드에 대한 ID얻기
객체의 메쏘드를 호출하기 위해 그 메쏘드의 ID를 획득해야 한다. 이것은 메쏘드의 이름과 시그너쳐를 이용하는데, 이름은 별 무리가 없겠으나, 시그너쳐는 까다롭다.
시그너쳐는 메쏘드의 인자 리스트와 반환 타입 정보를 스트링화한 것으로, 다음과 같은 규칙이 있다.
- 시그너쳐 : "(인자 리스트)반환값"으로 이루어진 스트링이다.
- 인자리스트의 인자들은 아래의 타입 기호에 따라 표기되며, 서로 ';'으로 구분된다.
- 반환값 역시 타입 기호에 따라 표시된다.
타입 기호는 다음과 같다. 이것은 자바 가상 머신 스펙에서 클래스 파일 포맷 부분에 등장하는 기호와 동일하다.
- 이들의 배열은 이들의 타입 기호 앞에 '['를 붙인다. 즉 int 배열은 [I가 된다.
- 클래스 타입의 경우, L뒤에 클래스명을 패키지명까지 포함해 나열하면 된다. 즉, String클래스인 경우, Ljava.lang.String이다.
이것은 수작업으로 할 경우, 실수가 많을 수 있으나, javap를 이용해, 쉽게 기호화된 시그너쳐를 확인할 수 있다.
javap -s -p Hello
Compiled from Hello.java
class Hello extends java.lang.Object {
static {};
/* ()V */
Hello();
/* ()V */
public static void coo(java.lang.String, java.lang.String);
/* (Ljava/lang/String;Ljava/lang/String;)V */
private void foo(java.lang.String, java.lang.String);
/* (Ljava/lang/String;Ljava/lang/String;)V */
public native boolean getBoolean(boolean);
/* (Z)Z */
public native byte getByte(byte);
/* (B)B */
public native char getChar(char);
/* (C)C */
public native double getDouble(double);
/* (D)D */
public native float getFloat(float);
/* (F)F */
public native java.lang.String getHello(java.lang.String);
/* (Ljava/lang/String;)Ljava/lang/String; */
public native int getInt(int);
/* (I)I */
public native int getIntArray(int[])[];
/* ([I)[I */
public native long getLong(long);
/* (J)J */
public native short getShort(short);
/* (S)S */
public static void main(java.lang.String[]);
/* ([Ljava/lang/String;)V */
}
이것은 다음과 같이 Hello클래스에 두 메쏘드를 추가한 후의 javap결과이다.
private void foo(String str,String str1) {
System.out.println("Hello.foo() = "+str+str1);
}
public static void coo(String str,String str1) {
System.out.println("Hello.coo() = "+str+str1);
}
이제 foo메쏘드의 ID를 획득해 보자.
// 클래스 정보 획득
jclass cls = (*env)->GetObjectClass(env, obj);
// 메쏘드 ID
jmethodID fooM = (*env)->GetMethodID(env, cls, "foo", "(Ljava/lang/String;Ljava/lang/String;)V");
// 그런 메쏘드가 없으면, 0반환
if(fooM == 0) {
printf("Method foo isn't found\n");
}
else {
......
}
인자 생성 및 메쏘드 호출
이제 메쏘드를 호출하는 일이 다음 순서가 되겠다. 물론 여기에 해당되는 함수들이 제공되는데, 이 함수들을 통해, 클래스 내의 메쏘드를 호출하므로, 메쏘드 ID와 더불어 메쏘드의 인자들을 리스트화해서 보내야 한다. 두 가지 방법이 있다.
- C의 va_list구조체를 이용한다.
- jvalue 유니온를 이용한다.
여기서는 jvalue 유니온을 이용해 보자. 그 구조는 다음과 같다.
typedef union jvalue {
jboolean z;
jbyte b;
jchar c;
jshort s;
jint i;
jlong j;
jfloat f;
jdouble d;
jobject l;
} jvalue;
그러면, 스트링 두 개를 인자로 받는 foo메쏘드를 호출해 보자. String은 객체이므로, l에 스트링 객체의 레퍼런스를 할당하면 된다.
jvalue* args;
.......
args = (jvalue*)malloc(sizeof(jvalue)*2);
args[0].l = (*env)->NewStringUTF(env,"oops");
args[1].l = (*env)->NewStringUTF(env,"la");
(*env)->CallVoidMethodA(env, obj, fooM,args ); // JNIEnv, jobject, Method ID, jvalue
여기에서는 foo가 void 타입이므로, CallVoidMethodA가 쓰였지만, 이 외에에도 반환값에 따라 여러 함수가 제공된다. 이들의 인자는 위와 동일하다.
- jboolean CallBooleanMethodA
- jbyte CallByteMethodA
- jchar CallCharMethodA
- jshort CallShortMethodA
- jint CallIntMethodA
- jfloat CallFloatMethodA
- jdouble CallDoubleMethodA
참고로, va_list를 이용하여 인자를 전달하는 함수들은 A로 끝나지 않고, V로 끝나는데, 역시 마지막 인자만 va_list타입으로 수정해 주면 된다.
정적 메쏘드 호출
정적 메쏘드 또한 호출할 수 있는 함수가 따로 있다.
메쏘드 ID : GetStaticMethodID함수 이용
jMethodID cooM = (*env)->GetStaticMethodID(env, cls, "coo", "(Ljava/lang/String;Ljava/lang/String;)V");
if(cooM == 0) {
printf("Method foo isn't found\n");
}
else { .....
}
인자 형성 방법은 동일하다.
메쏘드 호출 : CallStaticVoidMethodA 이용
cooM = (*env)->GetStaticMethodID(env, cls, "coo", "(Ljava/lang/String;Ljava/lang/String;)V");
if(cooM == 0) {
printf("Method foo isn't found\n");
}
else {
args = (jvalue*)malloc(sizeof(jvalue)*2);
args[0].l = (*env)->NewStringUTF(env,"papa");
args[1].l = (*env)->NewStringUTF(env,"ya");
(*env)->CallStaticVoidMethodA(env, cls, cooM,args );
}
여기서 주의할 것은 CallStaticVoidMethodA의 두 번째 인자는 jobject타입이 아닌, jclass타입이란 것이다. 클래스 메쏘드이니 당연하기도 하다.
상위 클래스의 메쏘드 호출
한 걸음 더 나아가 상위 클래스의 메쏘드도 호출할 수 있다. 여기에 해당되는 메쏘드는 모두 NonVirtual이라는 이름을 포함하고 있는데, c++을 배운 이라면, NonVirtual의 의미를 알고 있을 것이다.
상위 클래스 타입의 jclass 객체 획득
jclass sClass = (*env)->GetSuperclass(env,cls);
메쏘드 ID : GetMethodID함수 이용
superFooM = (*env)->GetMethodID(env, sClass, "foo", "(Ljava/lang/String;Ljava/lang/String;)V");
if(superFooM == 0) {
printf("Method foo isn't found\n");
}
else {
.....
}
메쏘드를 호출: CallNonvirtualVoidMethodA
args = (jvalue*)malloc(sizeof(jvalue)*2);
args[0].l = (*env)->NewStringUTF(env,"can");
args[1].l = (*env)->NewStringUTF(env,"dy");
(*env)->CallNonvirtualVoidMethodA(env,obj,sClass ,superFooM,args );
멤버 필드 접근
필드를 접근하는 방법 또한 메쏘드를 접근하는 방법과 크게 다르지 않다. 필드가 Private일지라도 접근할 수 있다. 이 또한 몇 가지 함수에 의존하고 있는데, 그 함수의 형식이 메쏘드를 호출하는 함수와 거의 유사하기 때문이다. 일단 다음의 기호를 잊지 말자.
- 이들의 배열은 이들의 타입 기호 앞에 '['를 붙인다. 즉 int 배열은 [I가 된다.
- 클래스 타입의 경우, L뒤에 클래스명을 패키지명까지 포함해 나열하면 된다. 즉, String클래스인 경우, Ljava.lang.String이다.
이제 Hello.java에 몇 가지 필드를 추가해 보자.
private int intVal;
private static int iStaticIntVal;
private String strVal = "Hello";
이를 재컴파일 후, javah를 실행하고, 새로이 생긴 함수의 선언부를 HelloImpl.c로 복사해 이것에 대해 추가적으로 구현해 보기로 하자.
필드를 접근하는 것은 두 단계로 이루어진다.
- 클래스와 필드의 이름과 타입을 이용해 필드의 ID를 얻어낸다.
- 필드의 ID와 객체를 이용해 실제 필드의 값을 얻어낸다.
인스턴스 필드 접근
먼저 필드의 ID를 얻어내기 위한 함수는 다음과 같다.
jfieldID GetFieldID(JNI_Env* env,jclass clazz, const char *name, const char *sig)
그리고, 인스턴스 필드를 접근하는 함수들은 다음과 같다.
1) Read 함수
- jobject GetObjectField(JNI_Env* env,jobject obj, jfieldID fieldID)
- jboolean GetBooleanField(JNI_Env* env,jobject obj, jfieldID fieldID)
- jbyte GetByteField(JNI_Env* env,jobject obj, jfieldID fieldID)
- jchar GetCharField(JNI_Env* env,jobject obj, jfieldID fieldID)
- jshort GetShortField(JNI_Env* env,jobject obj, jfieldID fieldID)
- jint GetIntField(JNI_Env* env,jobject obj, jfieldID fieldID)
- jlong GetLongField(JNI_Env* env,jobject obj, jfieldID fieldID)
- jfloat GetFloatField(JNI_Env* env,jobject obj, jfieldID fieldID)
- jdouble GetDoubleField(JNI_Env* env,jobject obj, jfieldID fieldID)
2) Write 함수
- void SetObjectField(JNI_Env* env,jobject obj, jfieldID fieldID, jobject val)
- void SetBooleanField(JNI_Env* env,jobject obj, jfieldID fieldID, jboolean val)
- void SetByteField(JNI_Env* env,jobject obj, jfieldID fieldID,jbyte val)
- void SetCharField(JNI_Env* env,jobject obj, jfieldID fieldID, jchar val)
- void SetShortField(JNI_Env* env,jobject obj, jfieldID fieldID,jshort val)
- void SetIntField(JNI_Env* env,jobject obj, jfieldID fieldID,jint val)
- void SetLongField(JNI_Env* env,jobject obj, jfieldID fieldID, jlong val)
- void SetFloatField(JNI_Env* env,jobject obj, jfieldID fieldID, jfloat val)
- void SetDoubleField(JNI_Env* env,jobject obj, jfieldID fieldID, jdouble val)
클래스 필드 접근
Static 필드를 접근하기 위해 먼저 ID를 얻어내야 한다.
jfieldID GetStaticFieldID(JNI_Env* env,jclass clazz, const char *name, const char *sig)
그리고, 필드를 접근하는 함수들은 다음과 같다.
Gettor 함수
- jobject GetStaticObjectField(JNI_Env* env,jclass clazz, jfieldID fieldID)
- jboolean GetStaticBooleanField(JNI_Env* env,jclass clazz, jfieldID fieldID)
- jbyte GetStaticByteField(JNI_Env* env,jclass clazz, jfieldID fieldID)
- jchar GetStaticCharField(JNI_Env* env,jclass clazz, jfieldID fieldID)
- jshort GetStaticShortField(JNI_Env* env,jclass clazz, jfieldID fieldID)
- jint GetStaticIntField(JNI_Env* env,jclass clazz, jfieldID fieldID)
- jlong GetStaticLongField(JNI_Env* env,jclass clazz, jfieldID fieldID)
- jfloat GetStaticFloatField(JNI_Env* env,jclass clazz, jfieldID fieldID)
- jdouble GetStaticDoubleField(JNI_Env* env,jclass clazz, jfieldID fieldID)
Settor 함수
- void SetStaticObjectField(JNI_Env* env,jclass clazz, jfieldID fieldID, jobject value)
- void SetStaticBooleanField(JNI_Env* env,jclass clazz, jfieldID fieldID, jint value)
- void SetStaticByteField(JNI_Env* env,jclass clazz, jfieldID fieldID, jbyte value)
- void SetStaticCharField(JNI_Env* env,jclass clazz, jfieldID fieldID, jchar value)
- void SetStaticShortField(JNI_Env* env,jclass clazz, jfieldID fieldID, jshort value)
- void SetStaticIntField(JNI_Env* env,jclass clazz, jfieldID fieldID, jint value)
- void SetStaticLongField(JNI_Env* env,jclass clazz, jfieldID fieldID, jlong value)
- void SetStaticFloatField(JNI_Env* env,jclass clazz, jfieldID fieldID, jfloat value)
- void SetStaticDoubleField(JNI_Env* env,jclass clazz, jfieldID fieldID, jdouble value)
예제
이제 이들을 사용해 Hello 클래스의 필드들을 접근해 보기로 하자. Hello.java에 native메쏘드인 다음을 추가하고 컴파일 후, HelloImpl.c에서, 다음을 중심으로 코딩해 보자.
정적 변수 접근
정적 필드인 iStaticIntVal 필드를 접근하여, 값을 읽어들인 후, 다시 2를 더해 값을 써 보자.
jfieldID jFieldId;
jint iStaticIntVal;
jclass cls = (*env)->GetObjectClass(env, jobj);
jFieldId = (*env)->GetStaticFieldID(env,cls,"iStaticIntVal","I");
if(jFieldId == 0) {
printf("Field iStaticIntVal not Found in Hello class\n");
return;
}
// 값을 읽어들인 후,
iStaticIntVal = (*env)->GetStaticIntField(env,cls,jFieldId);
// 2를 더해, 다시 그 값을 쓴다.
(*env)->SetStaticIntField(env,cls,jFieldId,(iStaticIntVal+2));
인스턴스 변수 접근
jint iVal;
jfieldID jFieldId;
jclass cls = (*env)->GetObjectClass(env, jobj);
jFieldId = (*env)->GetFieldID(env,cls,"intVal","I");
if(jFieldId == 0) {
printf("Field intVal not Found in Hello class\n");
return;
}
iVal = (*env)->GetIntField(env,jobj,jFieldId);
printf("iVal in C = %d\n",iVal);
(*env)->SetIntField(env,jobj,jFieldId,iVal);
그런데, 실제로 int를 가지고 실험해 본 결과, C에서 값을 잘 넘겨받는 것까지는 좋은데, 다시 자바로 값을 써 줄 때, 인자가 잘 전달되지 않는 현상을 보였다. 좀더 생각해 볼 문제이다.
스트링 접근
스트링은 객체이므로 객체를 접근하는 방식을 통해 접근해야 한다. 우선 GetFieldID 함수의 인자로 "Ljava/lang/String;"을 주목하면, 객체의 접근 방식과 동일함을 알 수 있다. 여기에서 세미콜론(;)을 빠뜨리면, 인식하지 못하므로 주의하기 바란다.
jstring jstr;
jfieldID jFieldId;
jclass cls = (*env)->GetObjectClass(env, jobj);
jFieldId = (*env)->GetFieldID(env,cls,"strVal","Ljava/lang/String;");
if(jFieldId == 0) {
printf("Field strVal not Found in Hello class\n");
return;
}
jstr = (*env)->GetObjectField(env,jobj,jFieldId);
(*env)->SetStaticIntField(env,cls,jFieldId,(iStaticIntVal+2));
str = (*env)->GetStringUTFChars(env, jstr, 0);
printf("Get String : %s\n",str);
새로운 스트링을 생성하여, 이것의 레퍼런스값을 str 필드에 할당하려면, 다음과 같이 한다.
jstr = (*env)->NewStringUTF(env, "123");
(*env)->SetObjectField(env, jobj, jFieldId, jstr);
기타 객체를 호출하는 방법도 스트링과 거의 동일하다. (*env)->GetObjectField(env,jobj,jFieldId);를 통해, jobject타입의 객체를 얻어낸 후, 필요에 따라 이 객체의 메쏘드를 호출하면 된다.
예외 사항
예외 사항 던지기
이제 예외 사항을 던지는 방법을 알아보자. 예외 사항들은 각각 클래스로 되어 있으므로, 이들의 클래스 정보를 얻어낸 후, 다음의 함수를 이용하면 된다.
jint ThrowNew(JNI_Env* env, jclass clazz, const char *msg)
Hello.java에서 testFieldAccess가 java.io.IOException을 던지도록 수정해 보자.
public native void testFieldAccess() throws java.io.IOException;
javac Hello.java
javah -jni Hello
이제 새로이 HelloImpl.c에서, testFieldAccess의 끝에 다음을 추가해 보자.
jclass eCls;
eCls = (*env)->FindClass(env, "java/io/IOException");
if(eCls != 0) {
(*env)->ThrowNew(env, eCls, "IOException from C");
}
예외 사항 감지하기
JNI의 C코드에서, 자바의 메쏘드를 호출했을 때.예외 사항이 돌아올 수 있다. 이 때, 감지하는 데 사용되는 함수는 다음과 같다.
이것은 jthrowable타입의 예외 사항 객체를 반환해 준다. 그 예외 사항에 정보를 출력하는 데 사용되는 함수도 제공된다.
그리고, 예외 사항이 처리된 후, 다시 예외 사항이 없는 것처럼 하려면, 다음과 같은 함수를 수행한다.
이제 Hello.java에 새로운 메쏘드를 추가해 보자.
public void returnException() throws java.io.IOException {
throw new java.io.IOException("IOException from Java");
}
이 메쏘드를 C에서 호출하면, 예외 사항이 그쪽으로 반환될 것이다. 이것을 처리하는 코드는 다음과 같다.
jmethodID jmId;
jthrowable jexcp;
jmId = (*env)->GetMethodID(env,cls,"returnException","()V");
if(jmId == 0) {
printf("Method returnException not found\n");
}
else {
(*env)->CallVoidMethod(env,jobj,jmId);
jexcp = (*env)->ExceptionOccurred(env);
if(jexcp) {
(*env)->ExceptionDescribe(env); // 예외 사항 정보 출력
(*env)->ExceptionClear(env);
}
}
가비지 콜렉션
강제 레퍼런스 해제
원래 네이티브 메쏘드 내의 로컬 변수들이나 전역 변수들이 각각 지니고 있는 자바 객체에 대한 레퍼런스는 네이티브 메쏘드가 끝난 후에야 비로소 없어진다. 따라서, 네이티브 메쏘드가 오랜 시간동안 수행될 경우, 초반에만 실질적으로 사용될 뿐, 후반부에서는 쓰이지 않는 객체의 레퍼런스조차 메쏘드 전체가 수행이 끝날 때까지 남아있게 되는 셈이다. 이때 강제로 레퍼런스를 무효화시킬 수 있는 방법이 있다. 다음의 함수를 사용하면 된다.
- void DeleteLocalRef(JNI_Env* env,jobject obj) // 지역 변수
- void DeleteGlobalRef(JNI_Env* env,jobject gref) // 전역 변수
동기화
synchronized블록과 같은 동기화 블록을 C 코드내에서 지정해야 할 때가 있다. 바로 쓰레드에 의해 네이티브 메쏘드가 호출되었을 때, 이 메쏘드가 공유 변수들을 접근할 수 있기 때문이다. 그러한 용도로 사용되는 함수는 다음과 같다.
- (*env)->MonitorEnter(JNI_Env* env,jobject obj);
- (*env)->MonitorExit(JNI_Env* env, jobject obj);
이 두 메쏘드 사이에 있는 코드들은 쓰레드들간에 동기화된다.